我们先来看题面,点进去之前可以先思考一下:
Given an array of integers nums containing n + 1 n + 1 n + 1 [ 1 , n ] [1, n] [ 1 , n ] n ≤ 1 0 5 n \le 10^5 n ≤ 1 0 5
There is only one repeated number in nums, return this repeated number.
You must solve the problem without modifying the array and using only constant extra space .
如果不看第三行,那么任意O ( n log n ) O(n \log n) O ( n log n ) O ( 1 ) O(1) O ( 1 ) [ 1 , n ] [1, n] [ 1 , n ] nums,也不能新开数组,那就只能考虑双指针解法了。
一个比较容易想到的做法是 binary search,既然值域在 [ 1 , n ] [1, n] [ 1 , n ] m i d = ⌊ 1 + n 2 ⌋ mid = \lfloor\frac{1+n}{2}\rfloor m i d = ⌊ 2 1 + n ⌋ num 中 x x x x ≤ m i d x \le mid x ≤ m i d [ 1 , m i d ] [1, mid] [ 1 , m i d ]
这里使用反证法,记[ c o n d i t i o n ] [condition] [ c o n d i t i o n ] 1 1 1 0 0 0
假设[ 1 , m i d ] [1, mid] [ 1 , m i d ] ∑ i = 1 n [ n u m i ≤ m i d ] = x \sum_{i=1}^n [num_i \le mid] = x ∑ i = 1 n [ n u m i ≤ m i d ] = x [ m i d + 1 , n ] [mid+1, n] [ m i d + 1 , n ] 0 0 0 1 1 1 ∑ i = 1 n [ n u m i > m i d ] ≤ n − m i d \sum_{i=1}^n [num_i > mid] \le n - mid ∑ i = 1 n [ n u m i > m i d ] ≤ n − m i d n + 1 ≤ x + n − m i d ≤ n n+1 \le x + n - mid \le n n + 1 ≤ x + n − m i d ≤ n
因此假设不成立,原结论正确,[ 1 , m i d ] [1, mid] [ 1 , m i d ]
有了上述的结论,我们可以断定当x ≤ m i d x \le mid x ≤ m i d [ m i d + 1 , n ] [mid+1, n] [ m i d + 1 , n ] x > m i d x > mid x > m i d [ 1 , m i d ] [1, mid] [ 1 , m i d ] [ 1 , m i d ] [1, mid] [ 1 , m i d ]
以上过程递归进行,总时间复杂度为 O ( n log n ) O(n \log n) O ( n log n )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def findDuplicate (self, nums: List [int ] ) -> int : low, high = 1 , len (nums) - 1 while low < high: mid = (low + high) // 2 count = 0 for num in nums: if num <= mid: count += 1 if count > mid: high = mid else : low = mid + 1 return low
但题面中还有一个 follow up:
Can you solve the problem in linear runtime complexity?
这便是 binary search 不能触及到的领域了。这里我选择直接放弃,然后知道了一个名为 Floyd’s cycle-finding 的算法,它也有一个别名叫 tortoise and the hare algorithm:算法过程如下:
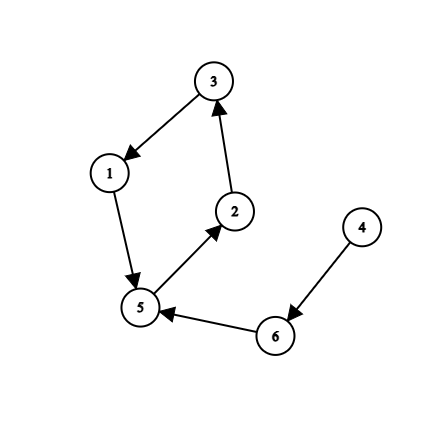
首先根据 nums 数组建图,数组的 index 是一个端点(这里 index 从 1 开始),而这个 index 对应的值则是这个端点指向的端点。例如以下数组:
对应了以下这个有向图:
首先 hare 和 tortoise 随机选一个点同时出发(为了演示方便,这里选择 4 号点),此时 hare 跑得快些,一次跑两步,tortoise 速度慢些,一次爬一步。于是便会有这样的情景(左 hare,右 tortoise):
这个时候 hare 与 tortoise 正式相遇了,这说明算法成功找到了一个环(不然 hare 只会永远在 tortoise 前面)。
然后算法的下一步为了找到环的“起始点”(也就是点 5。如果他们一开始就在环里那自然就是起点了)。将 tortoise 放回了起点 4,hare 保持原先位置 3 不动,随后它们每次走一步:
可以发现它们在环的“起始点” 5 处相遇了。可以证明,无论图的形状如何,它们始终都会在环的“起始点”处相遇:
设环的周长为C C C d d d 2 t 2t 2 t t t t C ∣ ( 2 t − t ) C | (2t - t) C ∣ ( 2 t − t ) 2 t 2t 2 t d d d 2 t + d 2t+d 2 t + d C ∣ 2 t C | 2t C ∣ 2 t
算法的最后一步就是 hare 不动,tortoise 绕一圈测出周长C C C
回到本题,由于重复的数字只有一个,所以肯定是“起始点”本身,因此我们只需要做算法的前两步即可 AC。时间复杂度 O ( n ) O(n) O ( n )
1 2 3 4 5 6 7 8 9 10 11 12 13 def findDuplicate (self, nums: List [int ] ) -> int : slow = nums[0 ] fast = nums[0 ] while True : slow = nums[slow] fast = nums[nums[fast]] if slow == fast: break fast = nums[0 ] while slow != fast: slow = nums[slow] fast = nums[fast] return fast
Brent 在 Floyd 的探圈算法基础上进行了改进,使用了 2 的幂次步长power来检测循环。并引入了lambda(每次迭代自增,可以理解为周长C C C mu(自增,最后得出尾巴 d d d
直接在第一步找到了环的周长C C C
每一次迭代只需要计算一次f f f
举一个例子,如果图长这样(假设它们都从 1 开始):
1 1 -> 2 -> 3 -> 4 -> 5 -> 3
然后我们有:
Frame 1 : Tortoise at 1, Hare at 2, power = 1, lambda = 1.Frame 2 : Tortoise at 2, Hare at 3, power = 2, lambda = 1.Frame 3 : Tortoise at 2, Hare at 4, power = 2, lambda = 2.Frame 4 : Tortoise at 4, Hare at 5, power = 4, lambda = 1.Frame 5 : Tortoise at 4, Hare at 3, power = 4, lambda = 2.Frame 6 : Tortoise at 4, Hare at 4, power = 4, lambda = 3 (cycle length detected).Frame 7 : Tortoise at 1, Hare at 1 (reset for finding position of length lambda).Frame 8 : Tortoise at 1, Hare at 2.Frame 9 : Tortoise at 1, Hare at 3.Frame 10 : Tortoise at 1, Hare at 4. (repeated lambda times)Frame 11 : Tortoise at 2, Hare at 5, mu = 1.Frame 12 : Tortoise at 3, Hare at 3, mu = 2. (cycle start found)
python 代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def brent (f, x0 ) -> (int , int ): """Brent's cycle detection algorithm.""" power = lam = 1 tortoise = x0 hare = f(x0) while tortoise != hare: if power == lam: tortoise = hare power *= 2 lam = 0 hare = f(hare) lam += 1 tortoise = hare = x0 for i in range (lam): hare = f(hare) mu = 0 while tortoise != hare: tortoise = f(tortoise) hare = f(hare) mu += 1 return lam, mu
由于这个建图很容易让人想起ρ \rho ρ R n R_n R n f ( x ) = ( x 2 + t ) m o d n f(x) = (x^2+t) \mod n f ( x ) = ( x 2 + t ) m o d n A = [ x , f ( x ) , f 2 ( x ) , ⋯ ] A = [x, f(x), f^2(x), \cdots] A = [ x , f ( x ) , f 2 ( x ) , ⋯ ] n = p q n=pq n = p q [ A i m o d p ] [A_i \mod p] [ A i m o d p ] O ( p ) O(\sqrt{p}) O ( p )
但我们事先不知道p p p gcd ( ∣ A i − A j ∣ , N ) \gcd(|A_i-A_j|, N) g cd( ∣ A i − A j ∣ , N ) A i ≡ A j m o d p A_i \equiv A_j \mod p A i ≡ A j m o d p ∣ A i − A j ∣ |A_i-A_j| ∣ A i − A j ∣ p p p gcd ( ∣ A i − A j ∣ , N ) \gcd(|A_i-A_j|, N) g cd( ∣ A i − A j ∣ , N )
那么我们如何来遍历这里的 i , j i,j i , j A A A m o d n \mod n m o d n A i m o d p A_i \mod p A i m o d p A j m o d p A_j \mod p A j m o d p F p F_p F p f f f F p F_p F p i , j i,j i , j p p p F q F_q F q q q q R n R_n R n n n n
这个算法便称为 pollard_rho 素性检测,因为 p p p O ( n ) O(\sqrt{n}) O ( n ) O ( n 1 / 4 ) O(n^{1/4}) O ( n 1 / 4 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from math import *def f (x, c, n ): return (x * x + c) % n def pollard_rho (n, max_attempts=10 ): if n % 2 == 0 : return 2 for attempt in range (max_attempts): x = random.randint(1 , n-1 ) y = x c = random.randint(1 , n-1 ) g = 1 while g == 1 : x = f(x, c, n) y = f(f(y, c, n), c, n) g = gcd(abs (x - y), n) if 1 < g < n: return g return n
为了水一篇论文 ,Brent 也使用了自己的算法替换了 pollard_rho 中的 Floyd 的探圈方法,并用实验证明了他的探圈方法效率比 Floyd 提高了 36%,从而导致总共的运行效率提高了 24%。
这里就不贴代码了,一种可能的实现参见:
https://comeoncodeon.wordpress.com/2010/09/18/pollard-rho-brent-integer-factorization/
就像将质因数分解问题联想到 DLP(离散对数问题)那样自然一样,除了在有限环R n R_n R n n n n
我们假设需要求解离散对数问题 α γ = β ( m o d n ) \alpha^\gamma=\beta \pmod n α γ = β ( m o d n ) n n n a , b , A , B a,b,A,B a , b , A , B α a β b = α A β B \alpha^a \beta^b = \alpha^A \beta^B α a β b = α A β B
α a α γ b = α A α γ B \alpha^a \alpha^{\gamma b} = \alpha^A \alpha^{\gamma B}
α a α γ b = α A α γ B
根据欧拉定理,我们有:
a + γ b = A + γ B ( m o d n − 1 ) a + \gamma b = A + \gamma B \pmod{n-1}
a + γ b = A + γ B ( m o d n − 1 )
( B − b ) γ = a − A ( m o d n − 1 ) (B-b)\gamma = a - A \pmod{n-1}
( B − b ) γ = a − A ( m o d n − 1 )
就可以通过 exgcd 求出对应的 γ \gamma γ
而对于如何找到这样的 a , b , A , B a,b,A,B a , b , A , B F n → F n \mathbb{F}_n\rightarrow\mathbb{F}_n F n → F n f ( x ) = x 2 + t m o d n f(x) = x^2+t \mod n f ( x ) = x 2 + t m o d n x i = α a i β b i x_i = \alpha^{a_i} \beta^{b_i} x i = α a i β b i F n \mathbb{F}_n F n
f ( x ) = { α x , if 0 ≤ x < p / 3 , x 2 , if p / 3 ≤ x < 2 p / 3 , β x , if 2 p / 3 ≤ x < p . f(x) =
\begin{cases}
\alpha x, & \text{if } 0 \leq x < p/3, \\
x^2, & \text{if } p/3 \leq x < 2p/3, \\
\beta x, & \text{if } 2p/3 \leq x < p.
\end{cases}
f ( x ) = ⎩ ⎪ ⎪ ⎨ ⎪ ⎪ ⎧ α x , x 2 , β x , if 0 ≤ x < p / 3 , if p / 3 ≤ x < 2 p / 3 , if 2 p / 3 ≤ x < p .
这里我们使用这个公式的变种:
f ( x ) = { x 2 , if x ≡ 0 m o d 3 , α x , if x ≡ 1 m o d 3 , β x , if x ≡ 2 m o d 3. f(x) =
\begin{cases}
x^2, & \text{if } x \equiv 0 \mod 3, \\
\alpha x, & \text{if } x \equiv 1 \mod 3, \\
\beta x, & \text{if } x \equiv 2 \mod 3.
\end{cases}
f ( x ) = ⎩ ⎪ ⎪ ⎨ ⎪ ⎪ ⎧ x 2 , α x , β x , if x ≡ 0 m o d 3 , if x ≡ 1 m o d 3 , if x ≡ 2 m o d 3 .
然后设初始值 tortoise 为 x = 1 , a = 0 , b = 0 x=1,a=0,b=0 x = 1 , a = 0 , b = 0 X = x , A = a , B = b X=x, A=a, B=b X = x , A = a , B = b A = [ 1 , f ( x ) , f 2 ( x ) , ⋯ ] A = [1, f(x), f^2(x), \cdots] A = [ 1 , f ( x ) , f 2 ( x ) , ⋯ ] X = f 2 ( X ) , x = f ( x ) X = f^2(X), x = f(x) X = f 2 ( X ) , x = f ( x ) a , b , A , B a,b,A,B a , b , A , B α a β b = α A β B \alpha^a \beta^b = \alpha^A \beta^B α a β b = α A β B
以下是n = 1019 , α = 2 , β = 5 n = 1019, \alpha = 2, \beta = 5 n = 1 0 1 9 , α = 2 , β = 5 x x x X X X
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 i x a b X A B ------------------------------ 1 2 1 0 10 1 1 2 10 1 1 100 2 2 3 20 2 1 1000 3 3 4 100 2 2 425 8 6 5 200 3 2 436 16 14 6 1000 3 3 284 17 15 7 981 4 3 986 17 17 8 425 8 6 194 17 19 .............................. 48 224 680 376 86 299 412 49 101 680 377 860 300 413 50 505 680 378 101 300 415 51 1010 681 378 1010 301 416
可以看到当a , b , A , B = 681 , 378 , 301 , 416 a, b, A, B = 681, 378, 301, 416 a , b , A , B = 6 8 1 , 3 7 8 , 3 0 1 , 4 1 6 ( B − b ) γ = a − A ( m o d n − 1 ) (B-b)\gamma = a - A \pmod{n-1} ( B − b ) γ = a − A ( m o d n − 1 ) 38 γ = 380 38 \gamma = 380 3 8 γ = 3 8 0 γ = 10 \gamma = 10 γ = 1 0 519 519 5 1 9
于是我们就在约τ n 2 \frac{\sqrt{\tau n}}{2} 2 τ n τ = 2 π \tau = 2\pi τ = 2 π O ( n ) O(\sqrt{n}) O ( n )
pohlig-hellman 算法也可以用于高效求解 DLP 问题,主要思路将 n − 1 n-1 n − 1 G F ( p ) \mathrm{GF}(p) G F ( p ) p p p
https://www.ruanx.net/pohlig-hellman/
若知道 DLP 中 n − 1 n-1 n − 1 O ( n ) O(\sqrt{n}) O ( n ) O ( p ) O(\sqrt{p}) O ( p ) p p p n − 1 n-1 n − 1
因此综上所述 DLP 这个问题取决于 n − 1 n-1 n − 1 n n n O ( n ) O(\sqrt{n}) O ( n ) n n n ∏ p i e i \prod p_i^{e_i} ∏ p i e i O ( ∑ e i p i ) O(\sum e_i \sqrt{p_i}) O ( ∑ e i p i )
An Introduction to Mathematical Cryptography
https://www.youtube.com/watch?v=pKO9UjSeLew
https://leetcode.com/problems/find-the-duplicate-number/solutions/4916414/c-2-optimal-approaches-o-n-and-o-nlogn-constant-space/
https://www.ruanx.net/pohlig-hellman/
https://en.wikipedia.org/wiki/Pollard's_rho_algorithm_for_logarithms
https://en.wikipedia.org/wiki/Pollard's_rho_algorithm
https://en.wikipedia.org/wiki/Pohlig–Hellman_algorithm
https://en.wikipedia.org/wiki/Cycle_detection#Brent.27s_algorithm
https://comeoncodeon.wordpress.com/2010/09/18/pollard-rho-brent-integer-factorization/
http://wwwmaths.anu.edu.au/~brent/pd/rpb051i.pdf