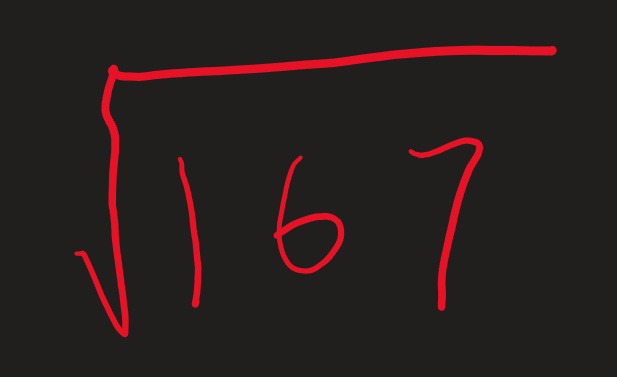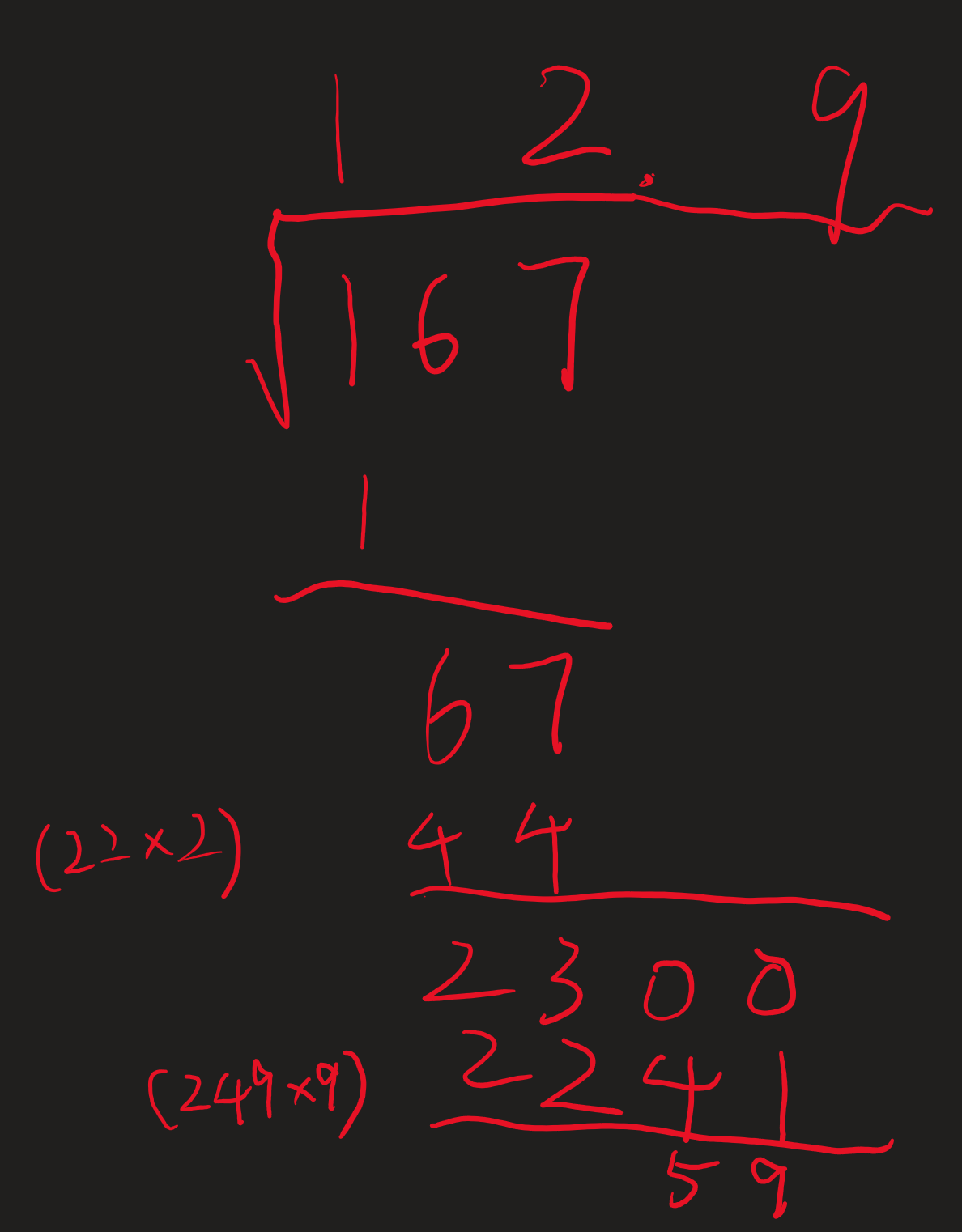def_20_p1(first, rem, next): """ recursively tries largest x from 0 to 9 to get (20 * first + x) * x <= rem * 100 + next return x and remainer """ x = 0
for i inrange(11): if (20 * first + i) * i > rem * 100 + next: x = i - 1 break assert i != 10 return (x, rem * 100 + next - (20 * first + x) * x)
这里的 first 指“初商”;rem
指当前遗留的余数,例如上一个例子的“0”,“23”,“59”;而 next
指下一位的数字,例如 “67”,“0”。
def_20_p1(first, rem, next): """ recursively tries largest x from 0 to 9 to get (20 * first + x) * x <= rem * 100 + next return x and remainer """ x = 0
for i inrange(11): if (20 * first + i) * i > rem * 100 + next: x = i - 1 break assert i != 10 return (x, rem * 100 + next - (20 * first + x) * x)
defgetintdigit(x): returnlen(str(x))
defsplit_two_by_two(s, first_len): if first_len == 0: first_len += 2 if first_len >= len(s): return [s]
first_chunk = s[:first_len] remaining = s[first_len:] rest_chunks = [remaining[i:i+2] for i inrange(0, len(remaining), 2)] return [first_chunk] + rest_chunks
defmysqrt(x, iters): """ Returns the square root of x. iters means keep {iters} valid digits. """ ifnotisinstance(iters, int) or (iters < 1): raise ValueError('iters must greater than 0') ifnotisinstance(x, int): raise ValueError('x must be an integer') if x < 0: raise ValueError('x must be non-negative')