From a LeetCode problem to a discrete logarithm solution algorithm
Let's first look at the problem statement. You can think about it before clicking in:
Given an array of integers
numscontainingintegers where each integer is in the range inclusive, . There is only one repeated number in
nums, return this repeated number.You must solve the problem without modifying the array and using only constant extra space.
Algorithm Solution Explanation
Without considering the third constraint, any nums or create a new array, then a two-pointer approach must be considered.
A relatively straightforward method is binary search. Given that the value range is nums that are
Here, we use proof by contradiction. Let
be when "condition" is true and otherwise. Assume there exists a duplicate element in
and . Since there is only one duplicate element, the elements in can only appear or times. Therefore, . Adding the two expressions gives , which is a contradiction! Hence, the assumption is false, and the original conclusion is correct: there are no duplicate elements in
.
With the above conclusion, we can assert that when
This process is performed recursively, with an overall time complexity of
def findDuplicate(self, nums: List[int]) -> int:
low, high = 1, len(nums) - 1
while low < high:
mid = (low + high) // 2
count = 0
for num in nums:
if num <= mid:
count += 1
if count > mid:
high = mid
else:
low = mid + 1
return low
Floyd's Cycle-Finding Algorithm
But there is a follow-up in the problem:
Can you solve the problem in linear runtime complexity?
This is where binary search falls short. Here, I chose to give up and learned about an algorithm called Floyd's cycle-finding algorithm, also known as the tortoise and hare algorithm. The process is as follows:
First, construct a graph from the nums array. The index of the array is one endpoint (here, the index starts from 1), and the value at that index is the endpoint it points to. For example, the following array:
[5,3,1,6,2,5]
Corresponds to the following directed graph:
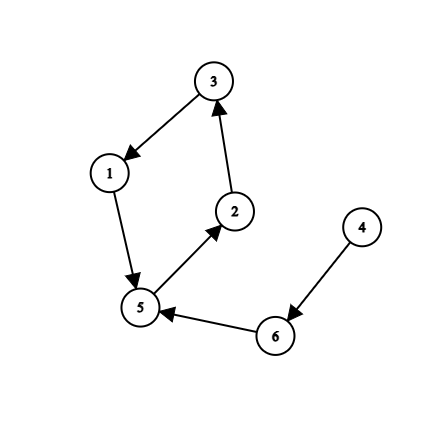
First, the hare and the tortoise start from a randomly chosen point (for demonstration purposes, we choose point 4). The hare moves faster, taking two steps at a time, while the tortoise moves slower, taking one step at a time. This leads to the following scenario (left: hare, right: tortoise):
4 4
5 6
3 5
5 2
3 3
At this point, the hare and the tortoise meet, indicating that the algorithm has successfully found a cycle (otherwise, the hare would always be ahead of the tortoise).
The next step of the algorithm is to find the "starting point" of the cycle (which is point 5. If they started inside the cycle, that would naturally be the starting point). The tortoise is moved back to the starting point 4, while the hare remains at its current position 3. Then, both move one step at a time:
3 4
1 6
5 5
It can be observed that they meet at the "starting point" of the cycle, point 5. It can be proven that, regardless of the shape of the graph, they will always meet at the "starting point" of the cycle:
Let the circumference of the cycle be
, and the length of the tail (i.e., the path 5->6->4 in the graph) be . When they first meet, the hare has taken steps, and the tortoise has taken steps. Clearly, we have . When the tortoise is moved back to the starting point, since they now move at the same speed, the distance between the hare and the tortoise remains constant at . When the tortoise takes steps to reach the "starting point", the hare takes steps. Since , the hare and the tortoise must meet, and they do so at the "starting point".
The final step of the algorithm is to keep the hare stationary while the tortoise moves around the cycle to measure the circumference
Returning to the problem, since there is only one duplicate number, it must be the "starting point" itself. Therefore, we only need to perform the first two steps of the algorithm to get AC. The time complexity is
def findDuplicate(self, nums: List[int]) -> int:
slow = nums[0]
fast = nums[0]
while True:
slow = nums[slow]
fast = nums[nums[fast]]
if slow == fast:
break
fast = nums[0]
while slow != fast:
slow = nums[slow]
fast = nums[fast]
return fast
Brent's Algorithm
Brent improved upon Floyd's cycle-finding algorithm by using powers of two step sizes (power) to detect cycles. It introduces lambda (which increments with each iteration and can be understood as the cycle length mu (which increments to eventually determine the tail length
- It directly finds the cycle length
in the first step. - Each iteration requires only one computation of
, compared to Floyd's three.
For example, consider the following graph (assuming all nodes start from 1):
1 -> 2 -> 3 -> 4 -> 5 -> 3
We then have:
- Frame 1: Tortoise at 1, Hare at 2,
power = 1,lambda = 1. - Frame 2: Tortoise at 2, Hare at 3,
power = 2,lambda = 1. - Frame 3: Tortoise at 2, Hare at 4,
power = 2,lambda = 2. - Frame 4: Tortoise at 4, Hare at 5,
power = 4,lambda = 1. - Frame 5: Tortoise at 4, Hare at 3,
power = 4,lambda = 2. - Frame 6: Tortoise at 4, Hare at 4,
power = 4,lambda = 3(cycle length detected). - Frame 7: Tortoise at 1, Hare at 1 (reset for finding position of length
lambda). - Frame 8: Tortoise at 1, Hare at 2.
- Frame 9: Tortoise at 1, Hare at 3.
- Frame 10: Tortoise at 1, Hare at 4. (repeated
lambdatimes) - Frame 11: Tortoise at 2, Hare at 5,
mu = 1. - Frame 12: Tortoise at 3, Hare at 3,
mu = 2. (cycle start found)
Python code is as follows:
def brent(f, x0) -> (int, int):
"""Brent's cycle detection algorithm."""
# main phase: search successive powers of two
power = lam = 1
tortoise = x0
hare = f(x0) # f(x0) is the element/node next to x0.
# this assumes there is a cycle; otherwise this loop won't terminate
while tortoise != hare:
if power == lam: # time to start a new power of two?
tortoise = hare
power *= 2
lam = 0
hare = f(hare)
lam += 1
# Find the position of the first repetition of length λ
tortoise = hare = x0
for i in range(lam):
# range(lam) produces a list with the values 0, 1, ... , lam-1
hare = f(hare)
# The distance between the hare and tortoise is now λ.
# Next, the hare and tortoise move at same speed until they agree
mu = 0
while tortoise != hare:
tortoise = f(tortoise)
hare = f(hare)
mu += 1
return lam, mu
pollard_rho
Since this graph structure easily brings to mind the Greek letter
However, we do not know the value of
So how do we traverse the indices
This algorithm is called the Pollard's rho algorithm for primality testing. Since, in the worst case,
from math import *
def f(x, c, n):
return (x * x + c) % n
def pollard_rho(n, max_attempts=10):
if n % 2 == 0:
return 2 # tackle even case
for attempt in range(max_attempts):
x = random.randint(1, n-1) # tortoise
y = x # hare
c = random.randint(1, n-1) # c of f(x)
g = 1 # GCD result
# Floyd's cycle-finding
while g == 1:
x = f(x, c, n) # tortoise takes 1 step
y = f(f(y, c, n), c, n) # hare takes 2 steps
g = gcd(abs(x - y), n) # calculate gcd
if 1 < g < n:
return g # non-trivial divisor
# retry
return n # max retries exceeded
Pollard's Rho Using Brent's Method
In order to hastily write a paper, Brent also replaced Floyd's cycle-finding method in Pollard's Rho with his own algorithm and experimentally demonstrated that his cycle detection method is 36% more efficient than Floyd's, resulting in an overall performance improvement of 24%.
The code won't be posted here, but one possible implementation can be found at:
https://comeoncodeon.wordpress.com/2010/09/18/pollard-rho-brent-integer-factorization/
Pollard's Rho for DLP
Just as it is natural to associate the prime factorization problem with the DLP (Discrete Logarithm Problem), Pollard himself extended the methodology of his rho algorithm—originally applied to factor integers in finite rings
Suppose we aim to solve the discrete logarithm problem
By Euler's theorem, this implies:
We can then solve for
The key challenge lies in finding such
Here, we use a variant of this formula:
We initialize the tortoise as
Below is an example for
i x a b X A B
------------------------------
1 2 1 0 10 1 1
2 10 1 1 100 2 2
3 20 2 1 1000 3 3
4 100 2 2 425 8 6
5 200 3 2 436 16 14
6 1000 3 3 284 17 15
7 981 4 3 986 17 17
8 425 8 6 194 17 19
..............................
48 224 680 376 86 299 412
49 101 680 377 860 300 413
50 505 680 378 101 300 415
51 1010 681 378 1010 301 416
A collision occurs when
Thus, a collision is found in approximately
Combining DLP with the Pohlig-Hellman Algorithm
The Pohlig-Hellman algorithm can also be used to efficiently solve the Discrete Logarithm Problem (DLP). The main idea is to factorize
If the prime factorization of
Therefore, in summary, the difficulty of the DLP depends on whether
Reference Materials
An Introduction to Mathematical Cryptography
https://www.youtube.com/watch?v=pKO9UjSeLew
https://www.ruanx.net/pohlig-hellman/
https://en.wikipedia.org/wiki/Pollard's_rho_algorithm_for_logarithms
https://en.wikipedia.org/wiki/Pollard's_rho_algorithm
https://en.wikipedia.org/wiki/Pohlig–Hellman_algorithm
https://en.wikipedia.org/wiki/Cycle_detection#Brent.27s_algorithm
https://comeoncodeon.wordpress.com/2010/09/18/pollard-rho-brent-integer-factorization/