The 100th blog
Three years ago in July, I wrote my first blog post and set a goal to publish 100 articles before finishing my undergraduate studies. Unexpectedly, I achieved this goal about half a year ahead of schedule.
Since "one hundred" is a special number, I believe the content of this blog should be related to the blog itself—otherwise, it wouldn't reflect the significance of this "special" post.
Introduction
In July three years ago, I wrote my first blog post and set a goal to publish 100 articles before graduating from my undergraduate studies. Surprisingly, I achieved this goal about half a year ahead of schedule.
Since "one hundred" is a special number, I believe the content of this blog should be related to the blog itself—otherwise, it wouldn't reflect the uniqueness of this milestone post.
I've always categorized meta-blog content under test, which previously included:
- Blog metadata-related content
- Blog maintenance records
- Blog functionality tests
However, there hasn't been a single post dedicated to the blog articles themselves—and that's exactly what this post is about. I'll analyze the following features related to the articles on this blog:
- Article publication time statistics
- Article length statistics
- Article tag distribution statistics
- Article category distribution statistics
- Article view count statistics
Article Publication Time Statistics
We can extract all md files under the _posts path and use the regular expression date:\s*(\d{4}-\d{1,2}-\d{1,2}\s+\d{1,2}:\d{2}:\d{2}) to extract the dates. We modified the actual date of a manually pinned article and removed one article from the beginning and one from the end, resulting in a total of 98 valid articles. The results are as follows:
2021-07-06 21:50:00
2021-07-07 20:10:00
2021-07-09 20:30:00
......
2024-12-07 02:00:00
2024-12-13 17:30:00
Using the time data from these 98 articles, we can leverage Python's pandas and matplotlib to accomplish the following tasks:
Relationship Between Cumulative Number of Articles and Time
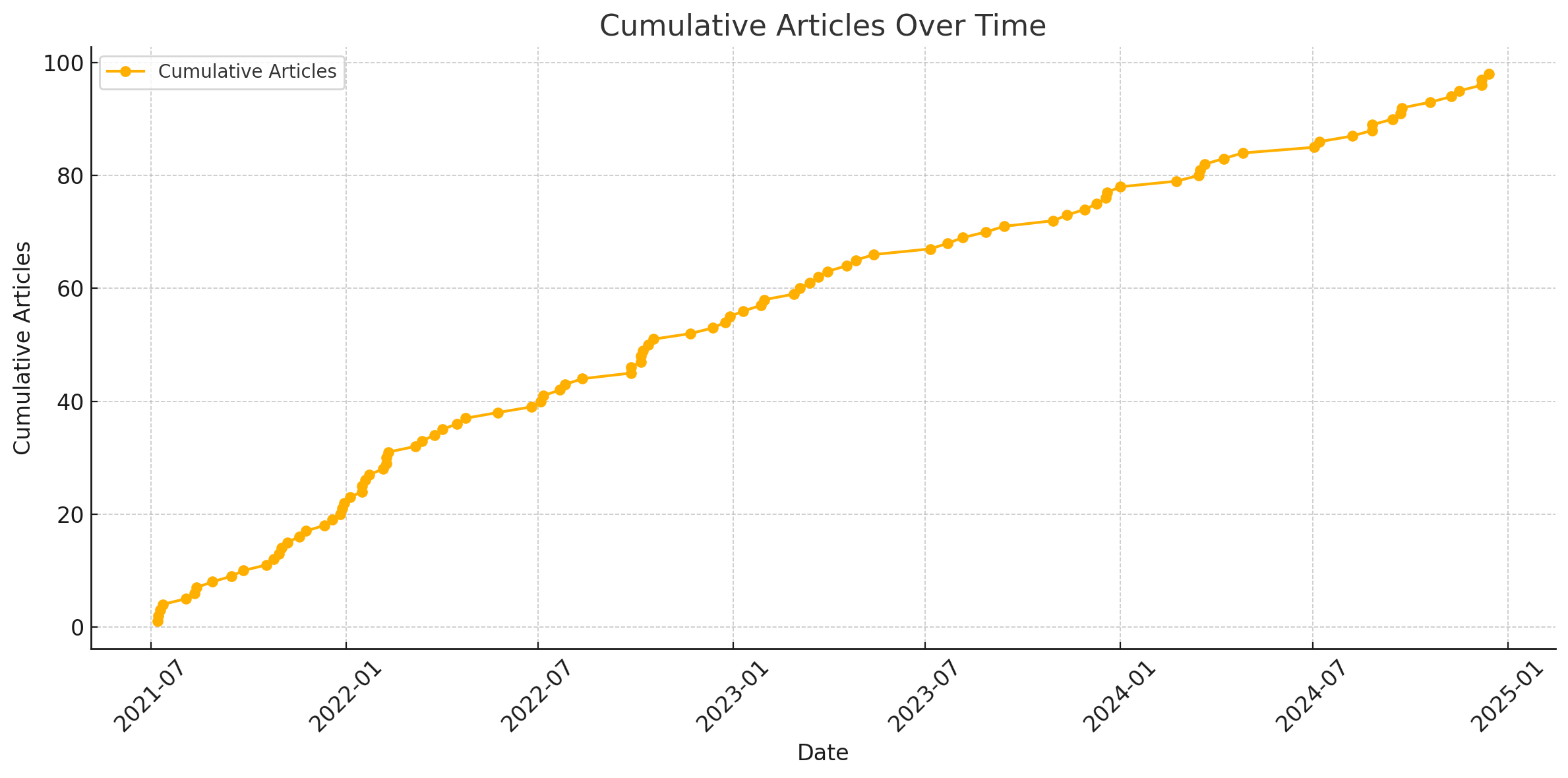
From the graph, it can be observed that the blog was updated quite frequently in the first half-year or so. After that, the frequency decreased, but the rate of change (derivative) remained nearly zero. This performance is much better than what I had anticipated, which was a sqrt-type or even a log-type growth pattern.
List the number of articles written each month from January to December
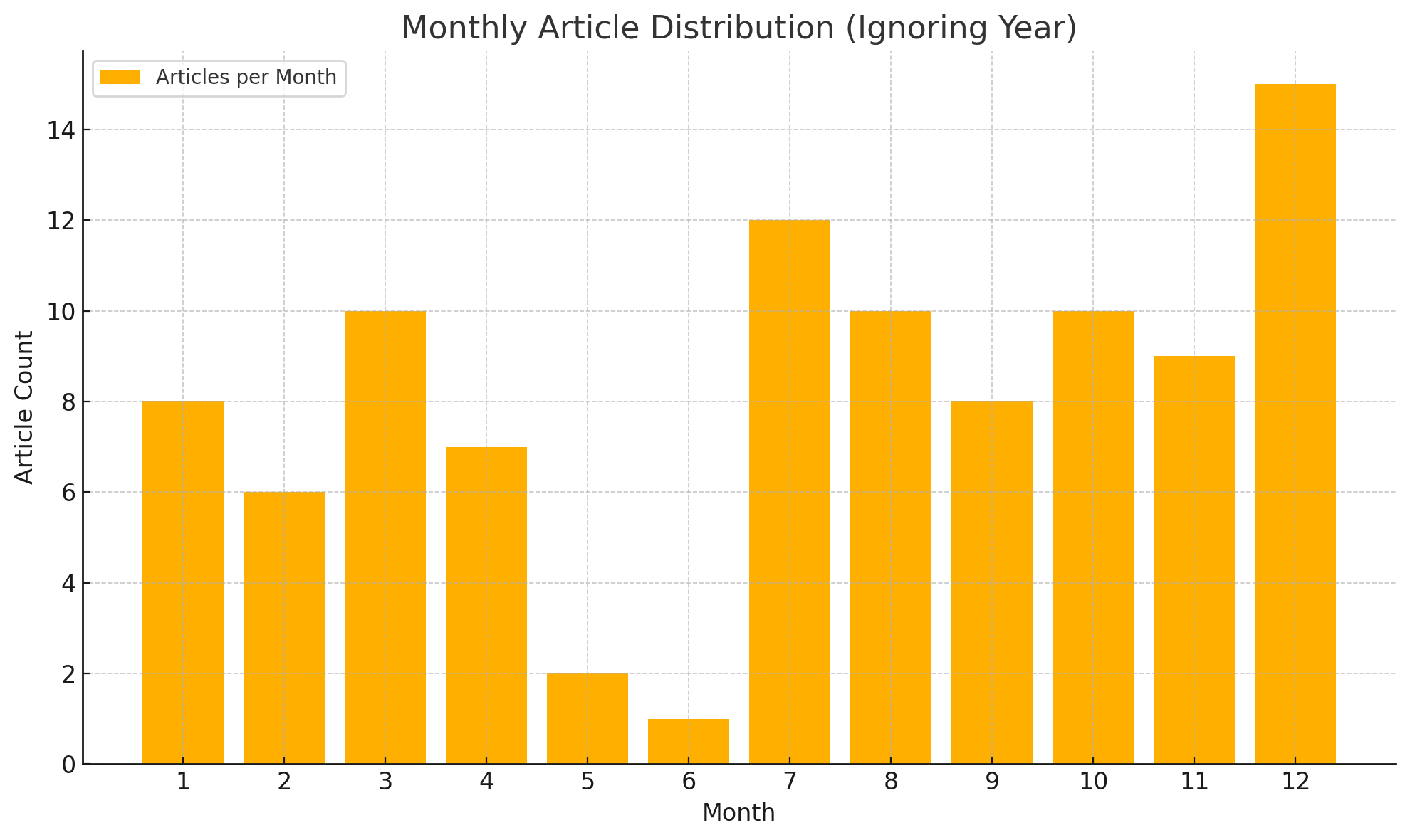
Since the blog started in July and it's only December now, our school definitely had training/military training in June, and I will definitely write a year-end summary in December, so this statistic meets expectations.
Relationship Between Number of Articles and Days of the Week
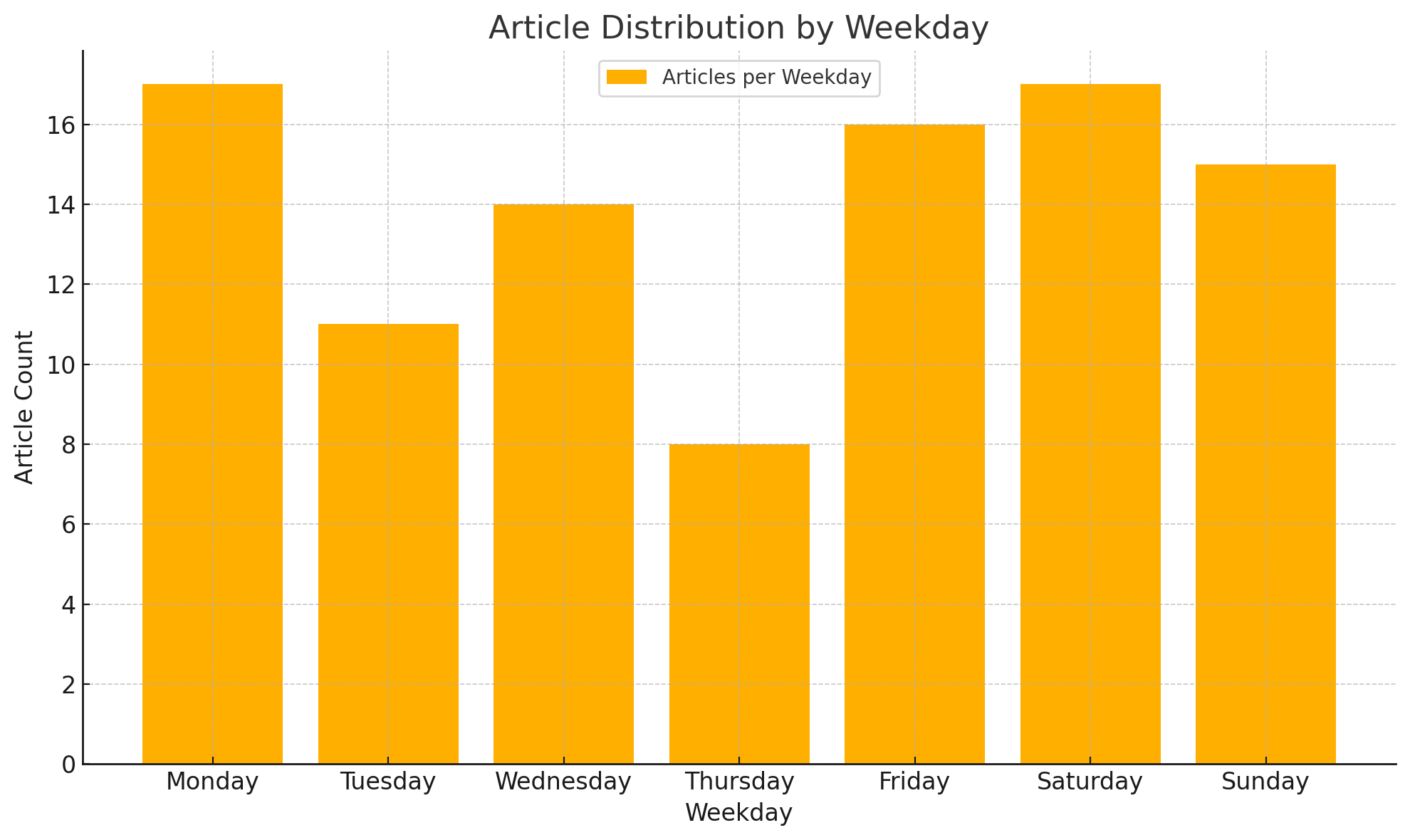
Not quite sure why there are fewer articles on Thursday—maybe it's just randomness.
List the time periods each day when articles are completed
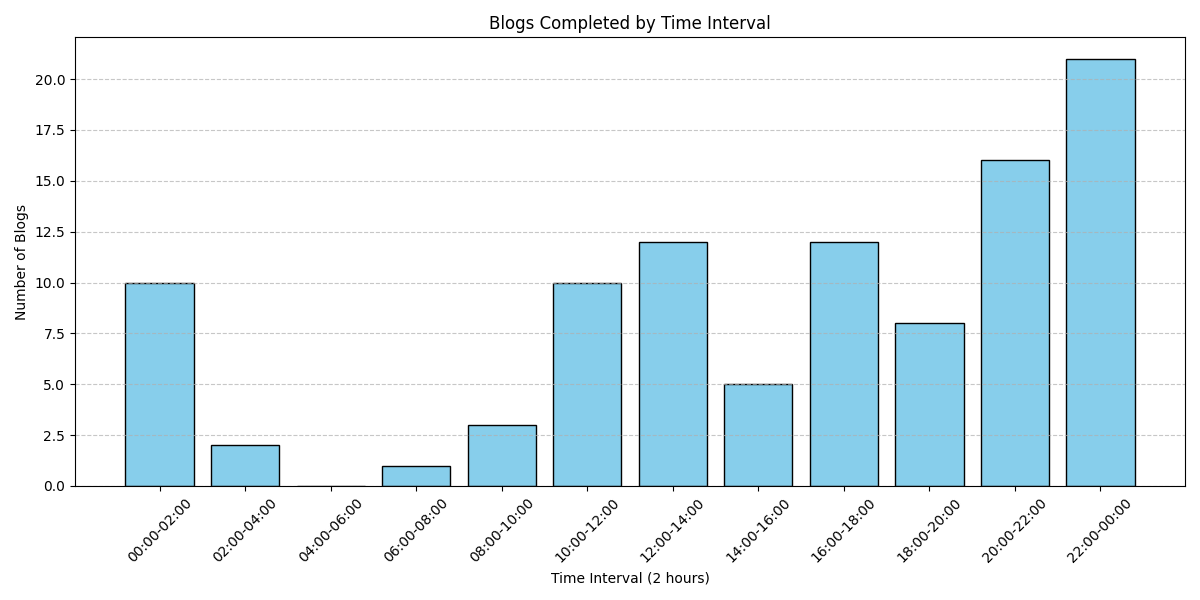
Evenings and afternoons are the peak writing periods.
Article Length Statistics
Here, I use the file size of the markdown files as the standard for length. First, let's list the largest and smallest data:
file size
0 bin_ctf.md 119478
1 零——十七.md 71098
2 ACGN.md 64258
3 canmv.md 49881
4 en_decrypt.md 49787
.. ... ...
95 asmmath.md 1120
96 1st_blog.md 1007
97 exgcd.md 892
98 meta.md 811
99 unlock-bl.md 527
The visualization result is as follows:
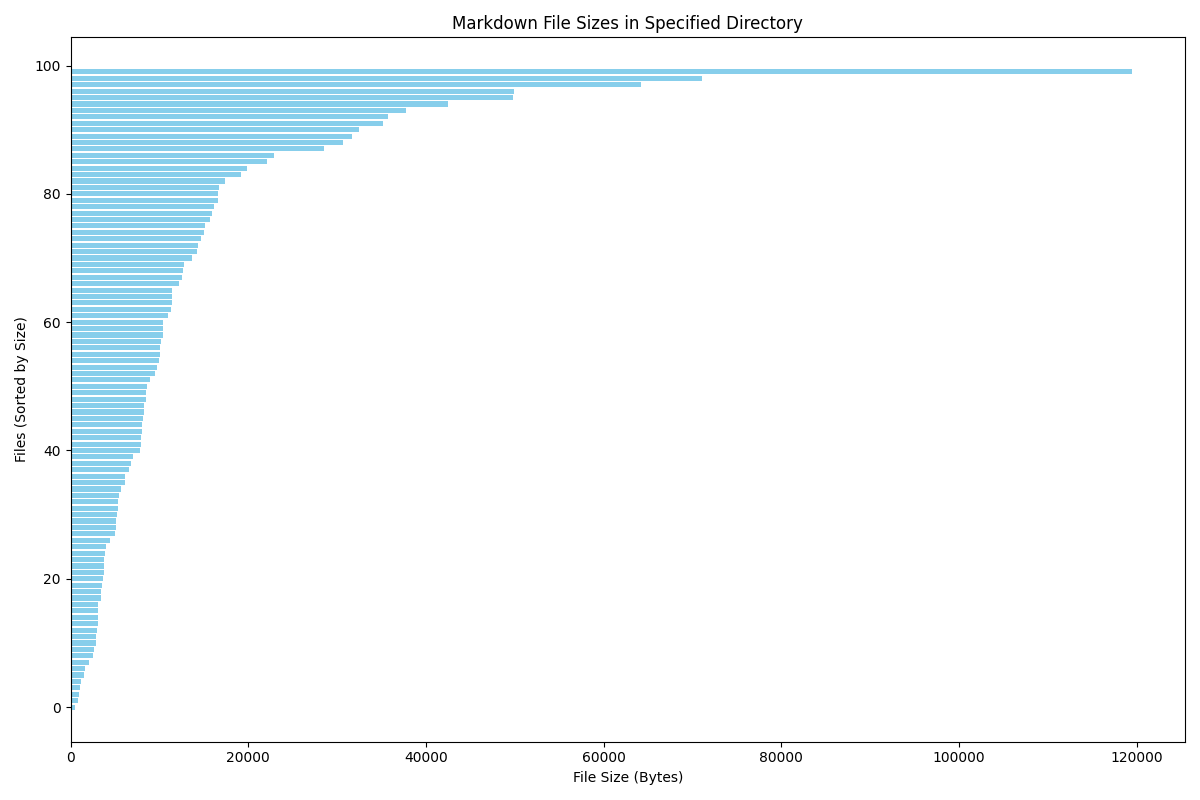
Functional Relationship Between Ranking and Length
Then we attempted to fit the curve using two types of functions:
- Power-law distribution
- Exponential distribution
The respective results obtained are as follows:
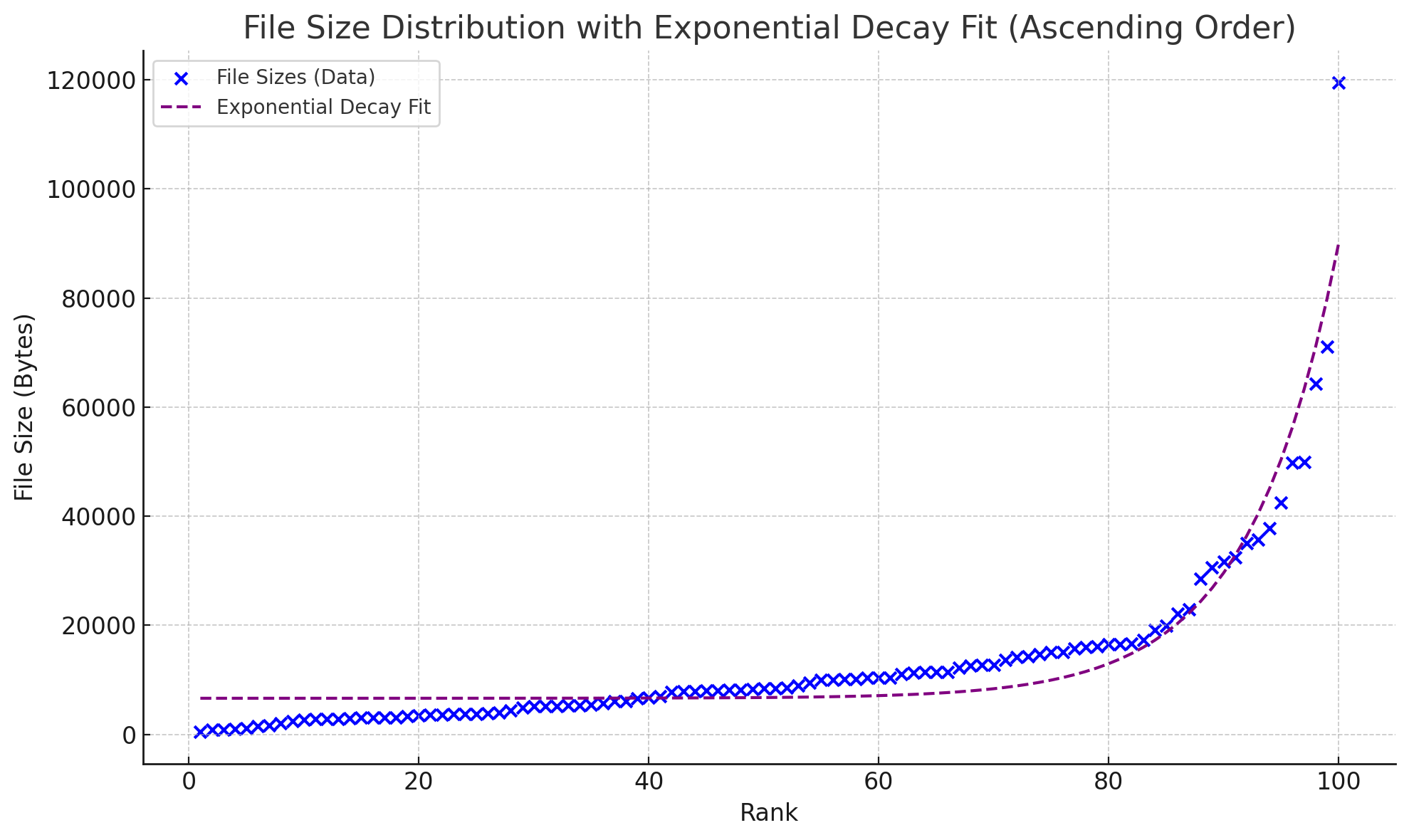
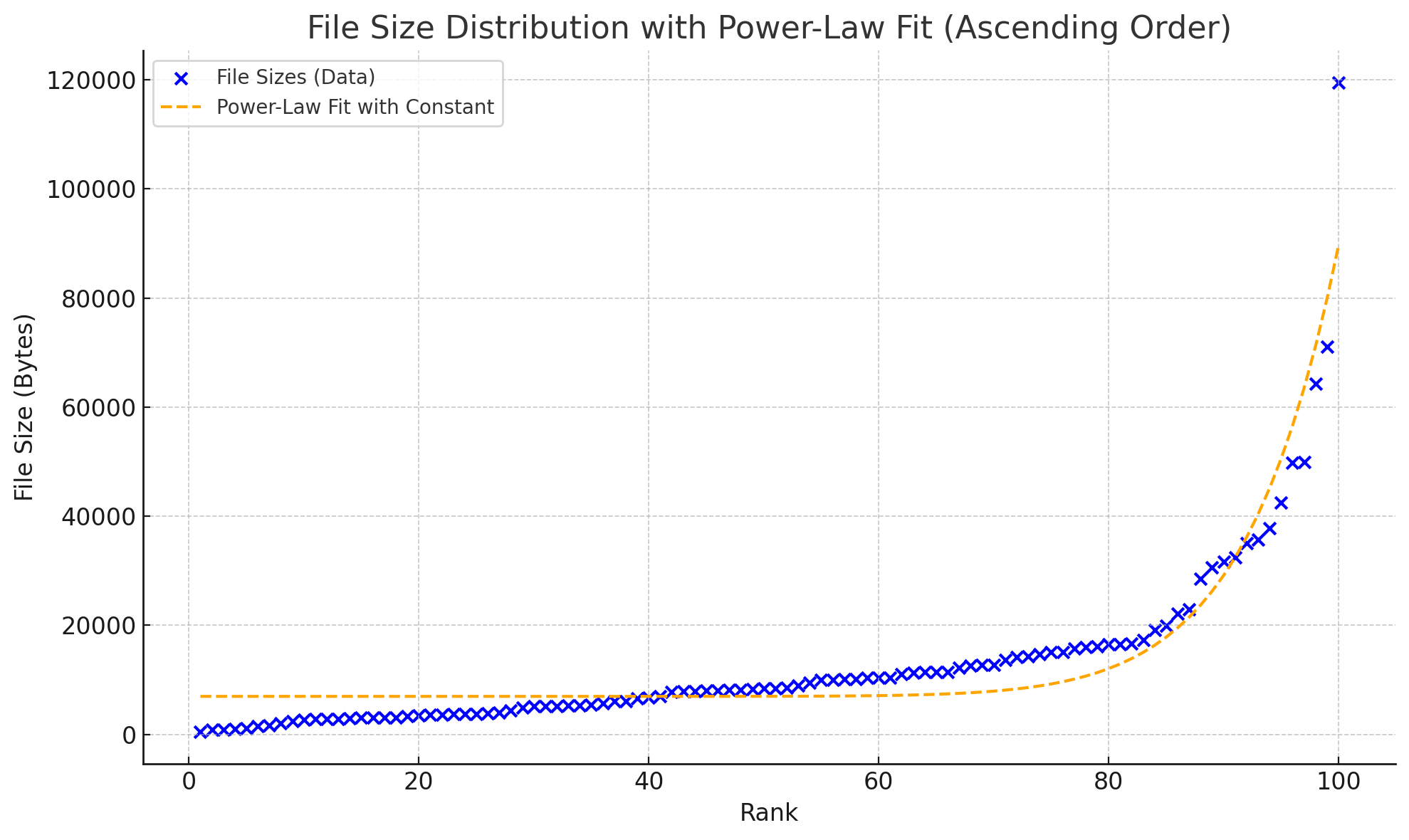
Can't see the difference? It becomes clear when they are placed together:
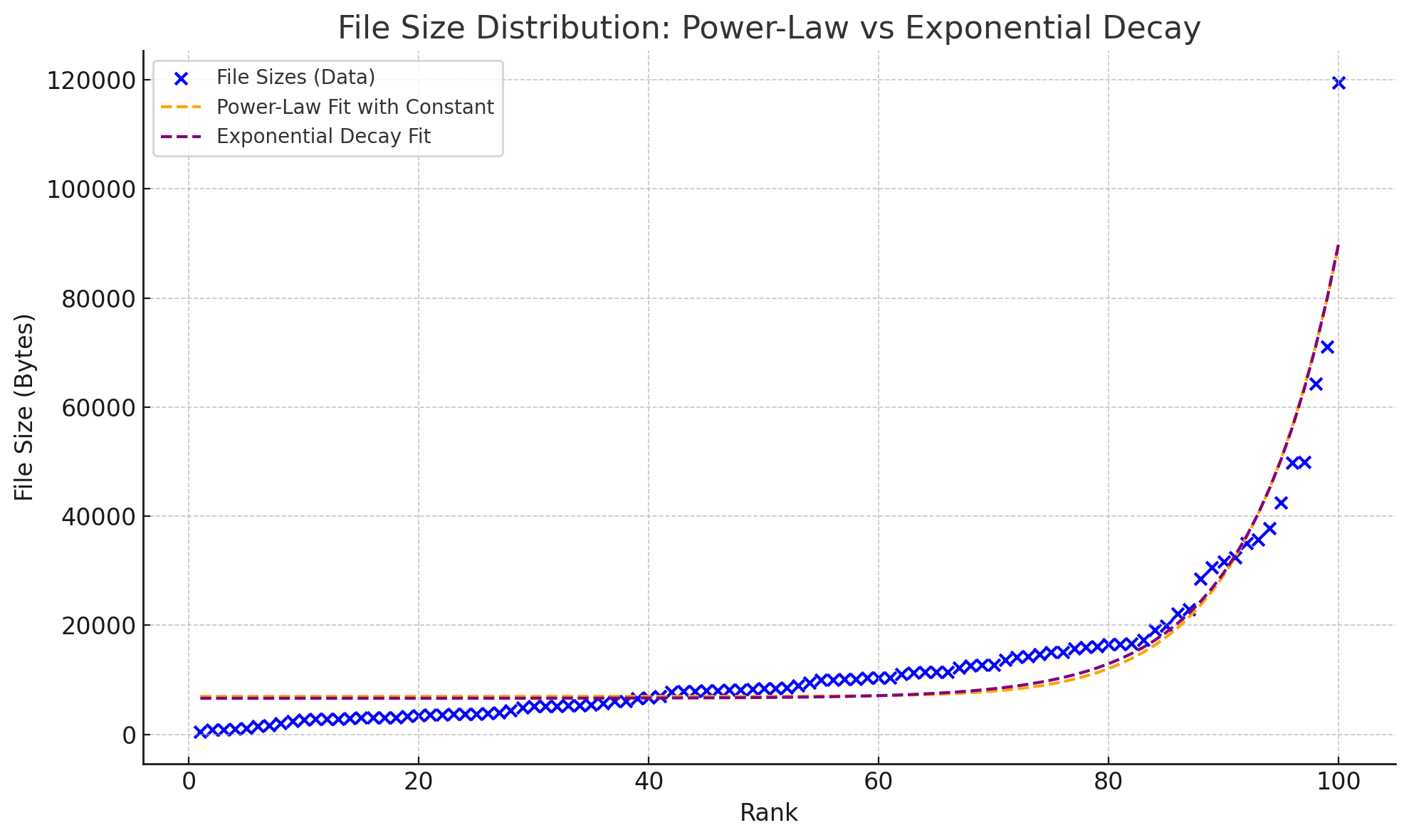
Through visual observation and residual calculation, the conclusion is that the exponential distribution is slightly more accurate.
Article Tag Distribution Statistics
Although the blog page already displays all tags and intuitively shows their frequency through size, I am more concerned with the yearly changes in tag frequency.
First, I used regular expressions to search for tags and dates, with the following results:
Tags: ['mma'], Date: 2021-8-2 18:20:00
Tags: ['encrypted'], Date: 2024-7-6 21:45:00
Tags: ['touhou', 'repost'], Date: 2023-3-14 10:00:00
Tags: ['touhou', 'javascript', 'linux', 'games'], Date: 2024-8-7 00:00:00
Tags: ['linux'], Date: 2023-8-5 15:15:00
......
Tags: ['repost'], Date: 2022-10-17 13:00:00
Tags: ['repost'], Date: 2021-7-11 22:50:00
Tags: ['encrypted'], Date: 2021-7-6 21:50:00
There are 68 lines in total, meaning about two-thirds of the blog posts have tags, which aligns with my expectations.
First, here is the overall ranking:
[('linux', 14),
('crypto', 13),
('python', 12),
('pwn', 11),
('repost', 9),
('reverse', 8),
('cpp', 7),
('web', 7),
('misc', 6),
('encrypted', 5),
('games', 5),
('assembly', 5),
('c', 4),
('android', 4),
('touhou', 3),
('windows', 3),
('javascript', 2),
('mma', 1),
('cmake', 1),
('docker', 1),
('verilog', 1)]
Next, we can categorize by year to obtain the rankings for each year (only the top five are shown here):
2021
cpp: 4 times
reverse: 4 times
crypto: 4 times
pwn: 4 times
python: 3 times
Just started learning CTF and Python, while also getting into cryptography, reverse engineering, and binary exploitation.
2022
pwn: 6 times
linux: 4 times
reverse: 4 times
crypto: 4 times
python: 4 times
Started extensively practicing binary exploitation challenges and began using Linux.
2023
repost: 3 times
linux: 3 times
touhou: 2 times
python: 2 times
android: 2 times
Continuing to use Linux, basically no longer playing CTF.
2024
linux: 6 times
crypto: 5 times
assembly: 3 times
python: 3 times
c: 2 times
Continuing with Linux, officially starting to delve into cryptography and system-related academic directions.
Python is the only one that has made the list all four years~
Article Category Distribution Statistics
While writing the categories, I encountered some strange errors that really tested the robustness of the code, such as:
- No tags followed the categories, causing the regular expression to match
---and treat--as part of the category. - The date was not in the 4-2-2 format, causing the regular expression to fail to match.
- Forgot to handle cases where the year was 2033, 2038, or 2021.
In the end, I managed to obtain the following results through a combination of scripting and manual editing of outliers:
2021
2021 Category Frequency:
blah: 9
ctf: 7
develop: 3
CP: 3
Jotting down random thoughts while learning CTF.
2022
2022 Category Frequency:
blah: 10
notes: 7
ctf: 6
develop: 6
test: 2
CP: 2
Continued learning CTF, academic theoretical course pressure began to increase, and gradually started learning how to "set up environments."
2023
2023 Category Frequency:
blah: 7
notes: 7
develop: 6
ctf: 2
test: 1
The pressure from theoretical courses and course projects at school persisted, while CTF and OI gradually faded out.
2024
2024 Category Frequency:
blah: 7
develop: 6
blah: 5
test: 2
Started getting involved in research projects, then had some notes for myself or others to read, as well as some of my own projects.
Article View Count Statistics
Now it's time for the lucky draw. Honestly, I'm not sure which articles readers are most interested in (after all, this is the chemical reaction between the PageRank algorithm and time). Let's see what the final results look like.
Since the divination operator uses JavaScript to fetch data, we can't directly use requests for web scraping here. Instead, we need to use a tool like Selenium.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
# Configure ChromeDriver and options
chrome_options = Options()
chrome_options.add_argument("--headless") # Headless mode
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--no-sandbox")
# Initialize WebDriver
service = Service('path/to/chromedriver') # Replace with your chromedriver path
driver = webdriver.Chrome(service=service, options=chrome_options)
# List of URLs
urls = [
"https://example.com/page1",
"https://example.com/page2",
# Add more links
]
# Store scraping results
results = []
# Iterate through the list of URLs
for url in urls:
try:
driver.get(url)
# Wait for specified elements to load
wait = WebDriverWait(driver, 10)
page_pv_element = wait.until(
EC.presence_of_element_located((By.ID, "busuanzi_value_page_pv"))
)
title_element = wait.until(
EC.presence_of_element_located((By.XPATH, '/html/body/main/div[2]/div[1]/article/header/h1'))
)
# Ensure page_pv_element.text is not empty
page_pv = None
retries = 5 # Try 5 times
while not page_pv and retries > 0:
page_pv = page_pv_element.text.strip()
if not page_pv:
time.sleep(1) # Wait 1 second before retrying
retries -= 1
# Get the title content
title = title_element.text
# Save the result
results.append({"url": url, "page_pv": page_pv, "title": title})
print(f"URL: {url}, Page PV: {page_pv}, Title: {title}")
except Exception as e:
print(f"Error processing {url}: {e}")
# Close the browser
driver.quit()
# Print all results
for result in results:
print(result)
—And now, the results are revealed. Here are the top 10:
How to Build an Ultimate Comfortable Pwn Environment, 1554
Three-Five—Android 14 Easter Egg Trial, 535
(Pinned, Completed) NJU-PA Experience, 493
(Pinned) Blog Metadata Overview, 294
How to Build an Ultimate Comfortable Pwn Environment (Season 3), 258
Is There Really Bad Luck in Mahjong Soul?, 198
Partial Clear Records of PwnCollege, 189
SCUCTF Freshman Competition—Team Yōuhuáng Zhōng Jiàn Tiān Writeup, 187
An Experience of Packet Capture for Grab App, 184
Reverse Engineering Generalized MT19937 Random Numbers, 184
It seems that setting up the environment is indeed a standout, becoming the content readers care about most (
As usual, I decided to plot the data and fit a curve:
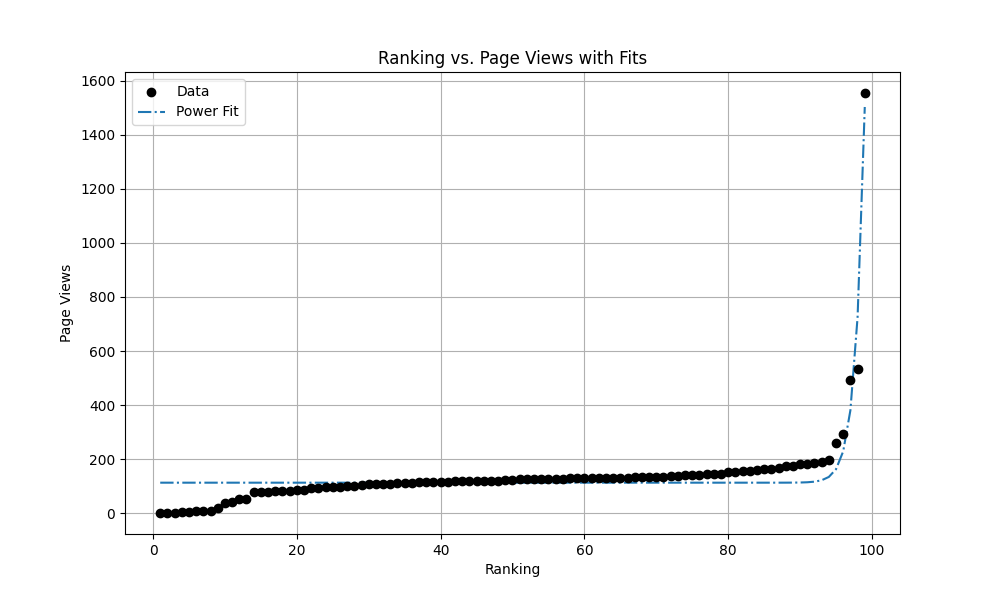
, a=1.2790748646693612e-158, b=80.69403536136282, c=113.09706403263824.
I feel like this constant term
The result of the exponential fit is too outrageous, so I won't include it here—