(archived) OS Notes
Only the theoretical portion is provided for final exam review.
Computer System Overview
More focused on computer organization, not tested in the exam.
- Fetch-Execute.
- Interruption: program flow chart, ISR (Interrupt Handler) level.
Operating System Overview
OS: a program that controls the execution of application programs and acts as an interface between applications and the computer hardware.
Interrupts: Early computer models did not have this capability. This feature gives the OS more flexibility in relinquishing control to and regaining control from user programs.
Process Description and Control
Process
Interleave, Strategy, Deadlock.
Definition:
- A program that is currently running (executing).
- An instance of a program executing on a computer.
- An entity that can be assigned to a processor and executed by it.
- An active unit characterized by a set of executing instructions, a current state, and a collection of associated system resources.
Components:
- ID
- State
Threads
Thread: Lightweight process.
Linux does not have kernel threads, while Windows does. The advantages of not having kernel threads include being lightweight and easier to manage.
Concurrency
Terminology
- Atomic operation
- Critical section
- Deadlock
- Livelock
- Mutual exclusion
- Race condition
- Starvation
Characteristics of single-program systems:
- Isolation
- Continuity
- Reproducibility
Characteristics of multi-program systems:
- Loss of isolation
- Intermittency
- Non-reproducibility
algorithm
Dekker

- Prone to livelock.
- Imposes a fixed execution order on processes, limiting flexibility.
- Complex implementation, making it difficult to verify.
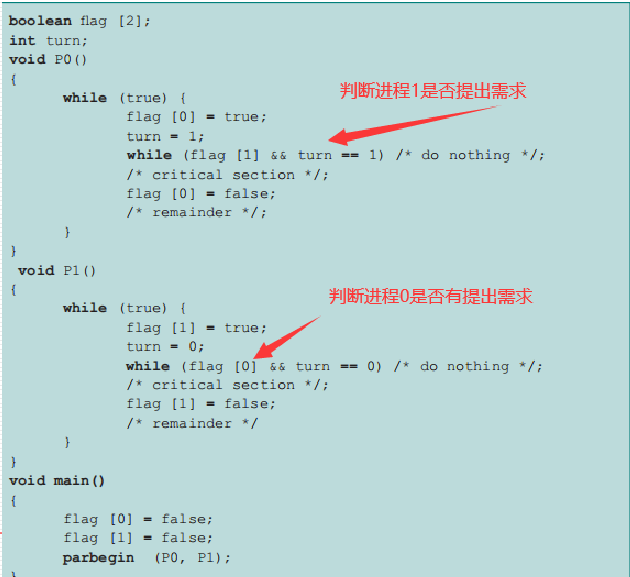
Peterson's Algorithm
Hardware Disabling
Disadvantages:
- The processor is limited in its ability to interleave programs.
- Disabling interrupts on one processor does not guarantee mutual exclusion in a multi-processor environment.
Special Instructions
Advantages: No limit on the number of processes, simple and easy to verify, supports multiple critical sections.
Disadvantages: Busy waiting, starvation, deadlock.
Semaphores
Terminology
- Binary Semaphore
- Counting Semaphore
- Mutex
- Strong Semaphore
- Weak Semaphore
Operations
- semwait: Request a resource / wait for a condition
- semsignal: Release a resource / generate a condition
- If both operations occur in the same process, it is called mutual exclusion; if they occur in different processes, it is called synchronization.
- For semwait, handle synchronization first, then mutual exclusion.
Steps
- Determine the number of processes
- Analyze the nature of the problem
- Define the semaphores and initialize their values
- Call semwait and semsignal in the processes
Semaphore(a, b, c)
{
a = 1;
b = 2;
c = 3;
}
void p_1...p_n()
{
// do something
}
void main()
{
Parbegin(p(1), p(2), p(3), ..., p(n));
}
Problems
Producer-Consumer Problem:
void producer() {
while (1) {
produce();
semwait(empty);
semwait(mutex);
// put item in store
semsignal(mutex);
semsignal(product);
}
}
void consumer() {
while(1) {
semwait(product);
semwait(mutex);
// take item from store
semsignal(mutex);
semsignal(empty);
use();
}
}
Reader-Writer Problem:
Mutual exclusion between readers and writers, and between writers and writers.
Mutual exclusion among readers (race condition).
Reader-Priority:
Semaphore mutex = 1; // File mutual exclusion
Semaphore read_mutex = 1; // Reader count mutual exclusion
int counter = 0;
void reader() {
int m;
semwait(read_mutex);
counter++;
semsignal(read_mutex);
if (counter == 1) semwait(mutex); // the first to read, compete with writer
read();
semwait(read_mutex);
counter--;
semsignal(read_mutex);
if (counter == 0) semsignal(mutex);
}
void writer() {
semwait(mutex);
write();
semsignal(mutex);
}
Equal-Priority:
Semaphore mutex = 1; // File mutual exclusion
Semaphore read_mutex = 1; // Reader count mutual exclusion
Semaphore queue = 1; // Reader and writer queuing mutual exclusion
int readcount = 0;
void reader() {
int m = 0;
semwait(queue);
semwait(read_mutex);
readcount++;
semsignal(read_mutex);
if (readcount == 1) semwait(mutex);
semsignal(queue);
read();
semwait(read_mutex);
readcount--;
semsignal(read_mutex);
if (readcount == 0) semsignal(mutex);
}
void writer() {
semwait(queue);
semwait(mutex);
write();
semsignal(mutex);
semsignal(queue);
}
Monitors
Composition
- Local data
- Condition variables
- Waiting area (queue)
cwait(cond)csignal(cond) - Procedures
- Initialization code
Inherently mutually exclusive. (At most one active procedure at any given time.)
Message Passing
send(dest, msg)
receive(src, msg)
Inherently synchronous.
Synchronous blocking: You're hungry, ask your mom to cook, and then you wait continuously.
Synchronous non-blocking: You're hungry, ask your mom to cook, you go play games, and occasionally ask if the food is ready.
Asynchronous blocking: You're hungry, ask your mom to cook, you go play games, your mom tells you when the food is ready, and you go eat.
Asynchronous non-blocking: You're hungry, ask your mom to cook, you go play games, your mom tells you the food is ready and brings it to you.
Advantage: Cross-host communication, usable in network programming.
Deadlock & Starvation
There is no universally effective solution.
Why Deadlock Occurs
- Limited resources
- Improper order of resource requests and releases
Resources
- Reusable resources (CPU, memory, databases, semaphores, etc.)
- Consumable resources (interrupts, signals, etc.)
Requirements
- Mutual exclusion
- Hold and wait
- No preemption
- Circular wait (the first three are necessary conditions; adding this one makes it sufficient)
resolve
Allow Deadlock
- Ostrich Algorithm (Ignore)
- Deadlock Detection
Specific algorithm for deadlock detection:
Example:
- Find a zero vector in the
Allocationmatrix.- Set
w = v.- Look for a row vector in the
Requestmatrix that is less thanw, mark it, clearA, and update thewvector.- Repeat step 3 until no more comparisons can be made (deadlock) or all processes are cleared (no deadlock).

- Deadlock Elimination (Terminate the process with the least CPU time used, least output, longest waiting time, or lowest priority)
Do Not Allow
- Deadlock Prevention (Static)
- No mutual exclusion (cost issues)
- No hold and wait; request all resources at once (feasible, but cannot determine which resources a process needs)
- Preemption (feasible, requires ensuring that preempted processes can be easily saved and restored)
- Define a linear ordering of circular wait (feasible, but does not consider the actual needs of processes)
- Deadlock Avoidance (Dynamic)
- Process initiation denial: for all j,
. - Banker's Algorithm (drawbacks: maximum resources, isolated consideration, fixed number of allocated resources, child processes cannot exit, high time and space complexity)
- Process initiation denial: for all j,
Banker's Algorithm Details:
Example:
- a)
— Simply verify all A, B, C, D. - b)
- c) (Safety detection algorithm) Compare a row of
with the vector. If is greater, update , until no more comparisons can be made (unsafe) or all processes are cleared (safe). - d) (Banker's algorithm) Add the new request to the
matrix (in this case, add to P5to get), then update the vector to , and perform step c again.

Dining Philosopher's Problem
Initial Solution (Incorrect)
Problem: Possible deadlock (all five philosophers take one fork)
sem p[i] = 1 from 0 to 4
void philosopher(int i) {
think();
wait(p[i]);
wait(p[(i+1)%5]);
eat();
signal(p[(i+1)%5]); // routine
signal(p[i]);
}
Solution 1:
sem p[i] = 1 from 0 to 4;
sem room = 4; // only four philosophers won't have deadlock
void philosopher(int i) {
think();
wait(room);
wait(p[i]);
wait(p[(i+1)%5]);
eat();
signal(p[(i+1)%5]); // routine
signal(p[i]);
signal(room);
}
Solution 2:
sem p[i] = 1 from 0 to 4;
void philosopher(int i) {
think();
min = min(i, (i+1)%5); // confines philosopher 0 and 4 (won't eat together)
max = max(i, (i+1)%5); // so at most 4 procs
wait(p[min]);
wait(p[max]);
eat();
signal(p[max]);
signal(p[min]);
}
Q: What about 2 dynamic algorithms?
(TODO)
Assume there are
Memory Management
- Fixed Partitioning, Dynamic Partitioning: Entirely loaded, non-partitioned.
- Simple Paging, Simple Segmentation: Entirely loaded, partitioned.
- Virtual Memory Paging, Virtual Memory Segmentation: Partially loaded, partitioned.
Fixed Partitioning
- Pros: Simple, low operating system overhead.
- Cons: Limits the number of active processes, small jobs cannot efficiently utilize partition space (internal fragmentation).
Dynamic Partitioning
- Pros: More efficient memory utilization, no internal fragmentation
- Cons: Requires compaction to address external fragmentation, low processor utilization
Generates external fragmentation (solved using compaction algorithms)
Placement algorithms (Best Fit, First Fit, Next Fit)
A process may occupy different memory locations during its lifecycle (due to compaction and swapping techniques).
Buddy System
Similar to a binary tree
Superior to fixed and dynamic partitioning, but internal fragmentation exists
Simple Paging
Definitions: Frame, Page, Segment
Each process has a page table, which indicates the location of the corresponding frame (physical) for each page (logical) of the process.
A logical address consists of a page number and an offset within that page. The page number is used to look up the frame number (first 6 bits) in the page table, which is then concatenated with the offset (10 bits) to form the physical address.
A small amount of internal fragmentation exists.
Simple Segmentation
Unlike process page tables which only maintain frame numbers, process segment tables maintain both the length and base address of segments.
A logical address consists of a segment number and an offset. The segment number is used to look up the corresponding base address (16 bits) in the segment table, which is then added to the offset (12 bits) to obtain the physical address.
External fragmentation exists.
Memory Management Requirements
- Relocation (physical address, logical address, relative address, base register, limit register)
- Protection (satisfied by hardware)
- Sharing (allowing multiple processes to access the same part of memory)
- Logical organization (programs are written using modules, which can be compiled separately and provide different protections)
- Physical organization (programmers are unaware of the client's memory limitations)
Homework:


Correction: Due to a mechanism called relocation (if X was originally at that location and later freed, reallocating with malloc will still place it at the same location instead of shifting left),
7.6.aremains8MB. The second question should be corrected to[3M, 8M].
Virtual Memory
- Fixed partitioning, dynamic partitioning: fully loaded, non-partitioned.
- Simple paging, simple segmentation: fully loaded, partitioned.
- Virtual memory paging, virtual memory segmentation: partially loaded, partitioned.
Virtual Memory Paging
In simple terms, it involves moving a portion of memory to the hard disk and loading it back into memory when needed.
If the page to be read is located on the disk, a page fault interrupt is triggered, blocking the process. After the page is loaded from the disk into memory, another interrupt is generated to resume execution. (Thus, a single page fault results in two interrupts. If the interrupt time exceeds the instruction execution time, it can cause "thrashing.")
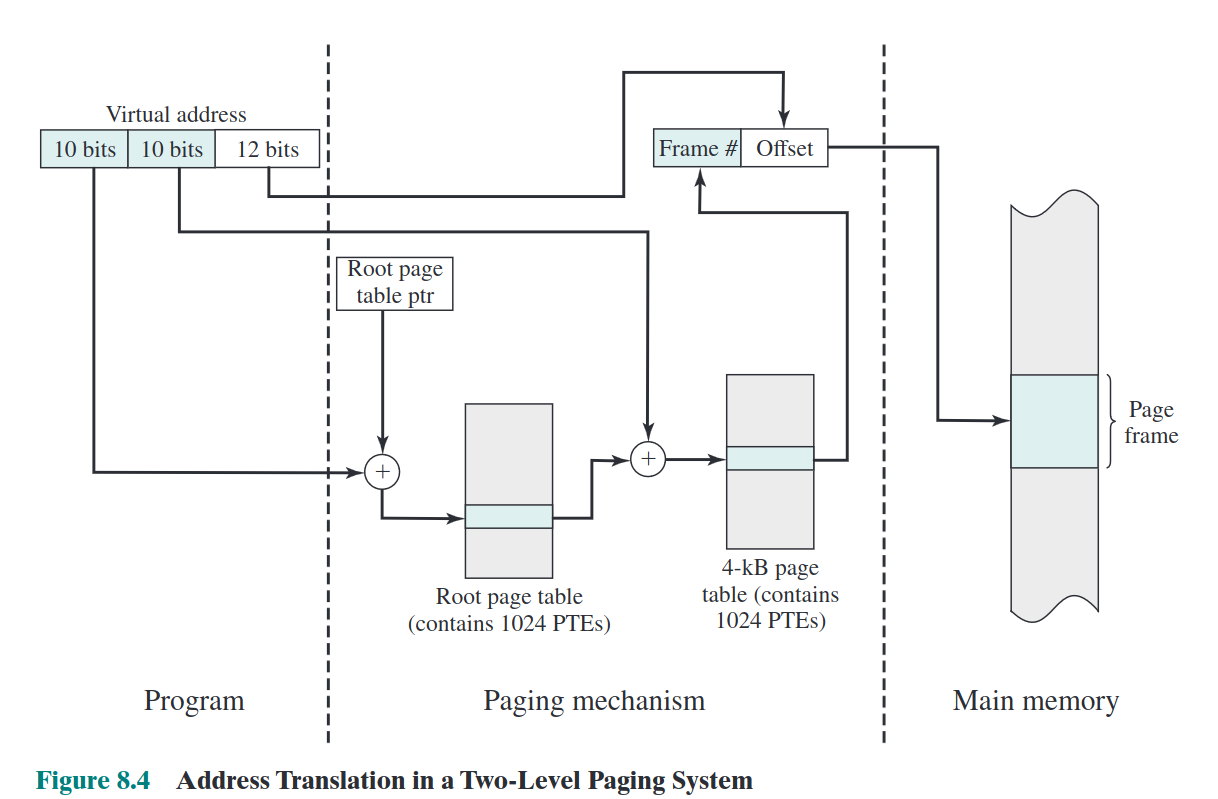
For 32-bit systems with 4GB of memory, the operating system maintains a 4KB root page table in memory (each entry is 4 bytes, totaling 1024 entries). Each entry in this root page table corresponds to a 4KB page table (each entry is 4 bytes, totaling 1024 entries per page table, resulting in 1,048,576 entries in total, occupying 4MB of virtual memory space). Each of these 4MB virtual memory entries maps to a 12-bit virtual memory address (thus, the 1,048,576 entries can map to the entire 4GB virtual memory space).
For pwners: This is why the last three bits of an address remain unchanged under ASLR. ASLR only randomizes at the page level, not the offset within a page.
The method for converting a virtual address to a physical address is as follows: First, use the first 10 bits as an offset into the root page table to locate the corresponding root page table entry. Then, determine whether the user page table (the 4MB one) corresponding to that root page table entry is in memory. If it is, use the next 10 bits to locate the corresponding user page table entry, and combine the page frame number from that entry with the offset to obtain the physical address. If it is not in memory, a page fault interrupt is triggered.
The Translation Lookaside Buffer (TLB) can cache some page number-to-frame number mappings, thereby reducing interrupts and improving memory access speed.
The relationship between page size and page fault rate first increases and then decreases (due to the principle of locality; the entire process resides within pages). The relationship between the number of page frames and the page fault rate is monotonically decreasing (if every page has a corresponding page frame, there would be no page faults).
Virtual Memory Segmentation
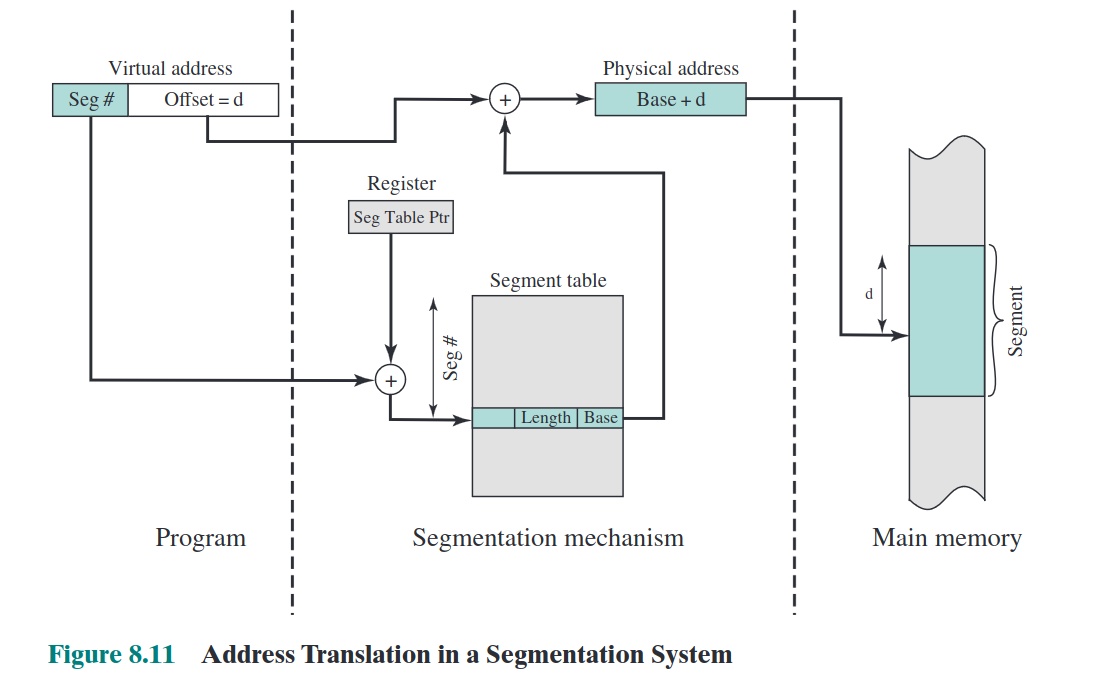
A virtual address consists of a page number and an offset. The method to convert it into a physical address is as follows: the page number is used as an offset to look up the corresponding segment number in the segment table, and the base address of that segment is added to the offset of the virtual address to obtain the physical address.
OS Level
Read Strategies
- On-demand Paging: Allocate only when required. (Results in many page faults at startup.)
- Pre-paging: Allocate a batch of pages at startup. (May include pages that are never accessed.)
Placement Strategy (Same as the Previous Placement Algorithm)
Determines the physical location where a process block resides.
Page Replacement Policies
Frame Locking: Pages that cannot be swapped out (e.g., kernel, etc.)
- OPT: Replace the page that will be accessed farthest in the future (ideal method, minimizes page faults, requires future access prediction)
- LRU: Least Recently Used (high overhead, requires timestamping each page)
- FIFO: First-In-First-Out (simplest, replaces the page that has been in memory the longest)
- CLK: Clock algorithm with a
usedbit (a compromise between LRU and FIFO) - PB: Prioritizes reducing I/O operation time
CLK Implementation Code:
pageSize = 3
pagePointer = 0
pages = [[0, 0] for i in range(pageSize)] # [page, used]
accessSeq = [2, 3, 2, 1, 5, 2, 4, 5, 3, 2, 5, 2]
def printPages():
print('pagePointer:', pagePointer)
for i in range(pageSize):
print(pages[i][0], pages[i][1])
for newPage in accessSeq:
hasPage = False
for i in range(pageSize):
if pages[i][0] == newPage:
pages[i][1] = 1
hasPage = True
break
if hasPage == True:
printPages()
continue
times = 0
for i in range(pageSize):
times += 1
if pages[pagePointer][1] == 0:
pages[pagePointer][0] = newPage
pages[pagePointer][1] = 1
pagePointer += 1
pagePointer %= pageSize
break
else:
pages[pagePointer][1] = 0
pagePointer += 1
pagePointer %= pageSize
if times == pageSize:
pages[pagePointer][0] = newPage
pages[pagePointer][1] = 1
pagePointer += 1
pagePointer %= pageSize
printPages()
Resident Set Management
- Fixed Allocation: The number of page frames allocated to a process is fixed.
- Variable Allocation: More frames are allocated if the page fault rate is high; fewer are allocated if the page fault rate is low.
- Local Replacement: Replace a page within the resident set of the faulting process.
- Global Replacement: Replace any unlocked page in the entire memory.
Clearance Strategies
- On-Demand Clearance: Pages are written back to auxiliary storage only when they are replaced.
- Preemptive Clearance: Pages are written back to auxiliary storage in advance.
Load Control
Affects the number of processes residing in memory (system concurrency) and processor utilization.
As the level of concurrency increases, processor utilization also increases. Beyond a certain point, the average resident set size becomes insufficient, leading to an increase in interruptions and a subsequent decrease in processor utilization.
Processor Scheduling
Types
- Long-term scheduling (job scheduling)
- Medium-term scheduling (swapping out processes)
- Short-term scheduling (system calls, I/O)
- I/O scheduling: deciding which process can use an available I/O device.
Algorithm Design
Requirements
(Non)preemptive: A process can be dispatched even if the currently executing process has not yet finished.
Performance:
- Turnaround time & response time
- Throughput & deadline
- Utilization
Fairness & starvation
algos
- non-preemptive
- FCFS: first come first serve
- not optimized for average turnaround time, throughput
- no starvation but biased toward long processes
- SPN: shortest process next
- scheduling repetitive tasks (OS doesn't know how long a process will execute)
- optimized turnaround time, throughput
- long process may starve, biased toward short processes
- HRRN: highest response ratio next
- equally treats performance and fairness
- avoids starvation of long processes to some extent
- FCFS: first come first serve
- preemptive
- RR: round robin
- depends on slice thickness
- short slice means quick response but long turnaround, and vice versa.
- SRT: shortest remaining time
- scheduling repetitive tasks (OS doesn't know how long a process will execute)
- more optimized turnaround time, throughput
- long process may starve, biased toward short processes
- MLFQ: multi-level feedback queue
- one queue for each priority level, new process priority is 0 (maximum)
- if released before interrupted, stay at same priority
- if preempted/interrupted, move to the next priority
- RR: round robin
Real-time scheduling
EDF
Earliest Deadline First
for non-scheduled
RM
Rate Monotonic (higher rate/frequency first)
for scheduling
I/O
ALL OPERATIONS ARE NON-PREEMPTIVE!!
Buffering
Aim: Reduce process stuck time to improve efficiency
Type
- Single buffer: Suitable for sequential data access, concurrent read/write not allowed.
- Double buffer: Enables concurrent read/write, still stuck if
& a new I/O request occurs. - Circular buffer: Circular queue (
).
Disk Scheduling
transfer (fixed)
rotation (fixed)
Disk Scheduling Algorithms
Policies:
- Priority (may lead to starvation for low-priority processes)
- FIFO (not optimized for performance)
- LIFO (not optimized, but suitable for transaction processing)
- SSTF (Shortest Seek Time First, faster than FIFO)
- SCAN (moves the arm in one direction, selects the closest request in the same direction, reverses direction upon reaching the end)
File
What
An abstraction to manage and access data.
Components
Field:
- Basic data element
- Contains a single value
- Of fixed or variable length
Record:
- Collection of related fields
- Basic unit of application data
- Of fixed or variable length
File:
- Collection of related records
- Managed as a single entity
- Identified and referenced by a name
Block:
- A continuous collection of data
- Contains part of a file
- Of fixed or variable length
- Basic unit of file storage allocation
- Basic unit of I/O buffering
requirements
- Persistent
- Shareable
- Structured
File Operation
Basic: create, delete, open, close, read, write
directory
abstraction to organize files
Single Level
- All user files are placed under a single root directory.
- Users must handle name conflicts (e.g., a malicious user deliberately overwriting files).
Two-Level Structure
- The first layer consists of users' folders, and the second layer contains users' files within their respective folders.
- Users are responsible for resolving any naming conflicts within their own files.
hierarchical
- used till now
Access Control
Typical levels:
- None
- Knowledge
- Execution
- Reading
- Appending
- Updating
- Changing protection
- Deletion
Access rights:
- Owner or privileged user (root): Full rights, grant rights to others
- Specific user: Individual user (associated with user ID)
- User group: Set of users
- Public
In *nix systems
- Access modes: Read, Write, eXecute (RWX)
- Access rights: Owner, group, public
- Access control grant:
rwxrwxrwx
File Organization
Criteria:
- Short access time
- Ease of update
- Economy of storage
- Simple maintenance
- Reliability (x)
Pile File
- Files are organized as not-fixed records
Easy to insert, difficult to search
Sequential File
- Files are organized as fixed, ordered records
- Has a key field
- New records are placed in a log file
Performance is still low
Index Sequential
- Add indexes to entries in a sequential file for quick searching
- Two-step search: index and record
- Overflow file
Indexed
- Sequential file builds indexes for one key field
- Index file builds indexes for multiple key fields
- No constraints on record position, no overflow file
After an operation, all records need modification
Direct File or Hashed File
- Indexed by a hash table, NOT sorted
- Update and search for a single record is easy
Storage Management
Goal: Manage the disk space to support a stream of file operations
Two basic tasks:
File Allocation
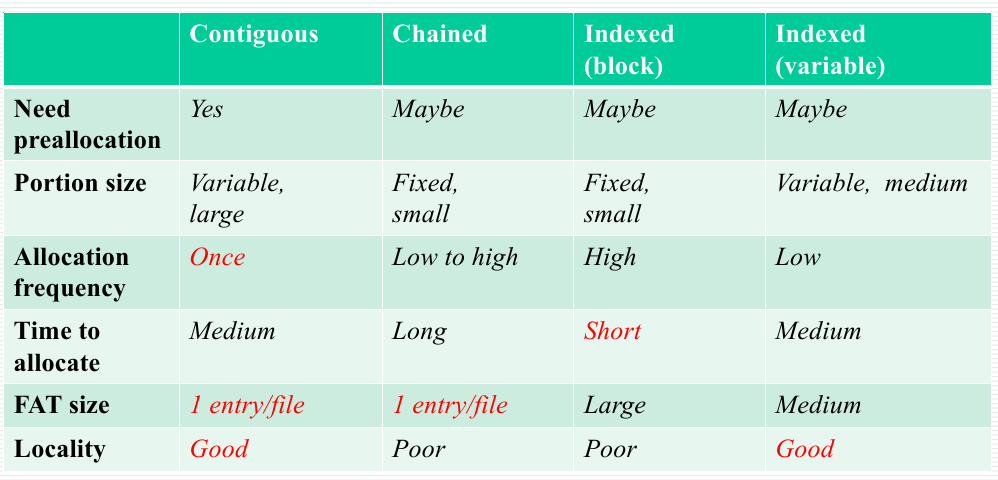
FAT: File Allocation Table
- Contiguous
- Good locality
- External fragmentation (improved by compression)
- Chained
- Each block has a pointer to the next block
- Poor locality (improved by consolidation)
- High utilization and flexibility
- Indexed (variable/block)
- FAT has a separate one-level index for each file
- The index contains an entry for each variable portion/block allocated to the file
- FAT contains the block number for the index block
Free Space Management
- DAT: Disk Allocation Table
- Bit table size (S), number of blocks (N), disk capacity (C), block size (s)
- Chained
- No DAT needed
- Fragmentation
- Long allocation/recycle time
- Indexed
- Free Block List
- Store the list of available blocks on the disk
- Consumes a small portion of disk space
- Some parts can be kept in memory to speed up operations
Review Outline
2
Concept of an Operating System (OS), and its distinction from application programs
Functions and objectives of an operating system
Core components of an operating system, with a brief description of their functions
Evolution of operating systems (batch processing, time-sharing, real-time systems)
Concepts of time-sharing systems and batch processing systems, and their differences
Roles of interrupts and exceptions in time-sharing and batch processing systems
How to understand the operating system as a virtual machine
3
What hardware support (interrupts and exceptions) does the CPU need to implement processes?
What is a process, and what is its relationship and difference with a program?
The concept and function of the Process Control Block (PCB), and a description of its composition
Describe how a program becomes a process from the perspective of its lifecycle
What primitives are related to process control?
The five-state diagram of a process (diagram-related)
Explain process execution from three perspectives (discussion topic)
The process creation flow, combined with Linux's fork (one call, two returns)
The flow and timing of process switching (wait)
4
Concept of Threads, Differences Between Processes and Threads
Three Implementation Methods of Threads
Advantages and Disadvantages of ULT and KLT
5
Four problems that concurrency needs to solve (synchronization, mutual exclusion, starvation, deadlock)
Why synchronization and mutual exclusion mechanisms are introduced (race condition)
What solutions exist (software-based, hardware-based, system-based (monitors and semaphores))
Drawbacks of hardware-based solutions
Concept, essence, and implementation of semaphores
What is a monitor, and why is it introduced
6
Concept and Background of Deadlock
Conditions for Deadlock (Three Sufficient Conditions, Four Necessary and Sufficient Conditions)
Solutions to Deadlock (Prevention, Avoidance, Detection, Ignoring)
Relationship Between Deadlock and Starvation
7
Seven Methods of Storage Management
Similarities and Differences Between Fixed Partitioning, Paging, Dynamic Partitioning, and Segmentation
Structure and Usage of Segment Tables and Page Tables
8
Three Issues to Consider in Implementing Virtual Memory
Three Methods for Implementing Virtual Memory (Virtual Segmentation, Virtual Paging, Segmented Paging)
Page Fault Handling Process in Virtual Memory
Address Translation Calculations
Briefly Describe the Relationship Between Page Fault Rate, Page Size, and Number of Page Frames
9
Descriptions of Long, Medium, and Short-Term Scheduling (Graph-Related)
10
Background of IObuffer and Its Operational Mechanism
12
File System Implementation Approaches
At the logical level, there are five implementation methods.
At the physical level, there are three implementation methods.
DIY Notes (Chapter 9)
DIY Textbook: Link to Operating Systems: Three Easy Pieces: https://pages.cs.wisc.edu/~remzi/OSTEP/
Chapter 7: Introduction
Response Time—A New Metric
The
STCFalgorithm primarily optimizes turnaround time, an approach mainly targeted at early batch systems. However, for today's time-shared systems, response time is the key factor determining real-time performance.
The formula for response time is as follows:
Suppose three processes
A,B, andCall enter the queue at time, and each has an execution time of 5. The scheduling using STCF/SJFis illustrated in the figure below: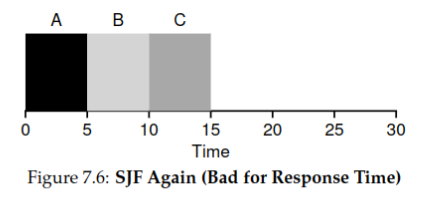
Thus, the average response time is:
Round Robin
The Round-Robin algorithm is a preemptive algorithm that significantly improves the response time of each process. Instead of running a job to completion, RR runs it for a time slice (also known as a scheduling quantum). It is important to note that the length of the time slice must be a multiple of the timer interrupt period. For example, if the timer interrupts every 10 milliseconds, the time slice could be 10, 20, or any other multiple of 10ms.
Using the same example as before, the scheduling scenario with
Round-Robin(with a time slice of 1 unit) is as follows: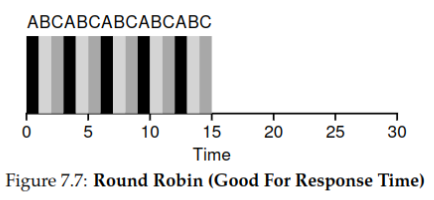
Therefore, the average response time is:
The improvement is significant.
Advantages:
- Significantly reduces response time
- Fair to processes
Disadvantages:
- Slow turnaround time
Considering I/O Situations
Conclusion: When using non-preemptive scheduling algorithms (such as STCF), the time chunks of processes that frequently use I/O should be split apart to improve resource utilization.
Example: Both
AandBare processes requiring 50ms, butAcalls I/O every 10ms, taking 10ms each time.Without splitting time chunks, total time used is 140ms:
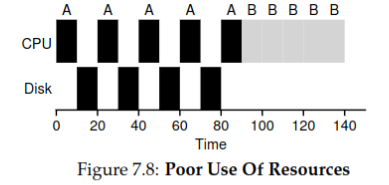
With splitting time chunks, total time used is 100ms:
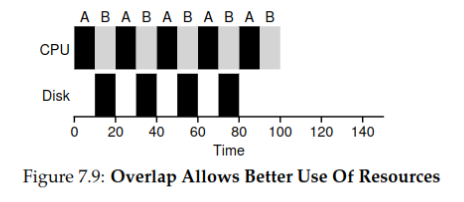
By treating each CPU burst as a separate job, the scheduler ensures that "interactive" processes run frequently. When these interactive jobs perform I/O, other CPU-intensive jobs can run, thereby making better use of the processor.
What to Do If the Future Cannot Be Predicted
The STCF/SJF algorithms have limited utility in real operating systems because the OS has little prior knowledge about each process. Potential improvements may include:
- Attempting to enhance algorithms like
Round-Robin, which do not require prior knowledge, such as by adjusting the length of time slices to balance response time and turnaround time. - Trying to predict the time required by processes.
Summary
In this chapter, we learned about:
- Optimizing response time:
Round-Robin - Handling I/O behavior in scheduling
Chapter 8: Multi-Level Feedback Queue
Problems MLFQ Attempts to Optimize
-
Optimizing turnaround time without prior knowledge of how long a job will run.
-
Reducing response time for interactive users while optimizing turnaround time.
Basic Concepts of MLFQ
MLFQ has multiple different queues, each assigned a different priority level. At any given time, a ready job resides in one of these queues, and MLFQ uses priority to decide which job to run.
Basic Rules of MLFQ
- Rule 1: If Job A has a higher priority than Job B, run Job A.
- Rule 2: If Job A and Job B have the same priority, run them alternately.
- Rule 3: When a job enters the system, it is placed in the highest priority queue (the topmost queue).
- Rule 4: Once a job uses up its time slice at its current priority level, its priority is decreased.
- Rule 5: After a specific period S, all jobs are moved to the highest priority queue.
Specific Implementation of MLFQ
Step 1
When a job first enters, it is placed in the highest priority queue for execution.
Step 2
Each queue is assigned a specific quantum length. If a job consumes its entire quantum, it is demoted to the next lower priority queue.
- The quantum length increases progressively from the highest priority queue to the lowest priority queue.
- If a job voluntarily relinquishes the CPU (e.g., due to I/O), it remains at the same priority level upon resumption and continues using the remaining quantum.
Step 3
After a certain period, all jobs are moved back to the highest priority queue.
Issues with MLFQ
- Starvation Problem: If there are "too many" interactive jobs in the system, they can collectively consume all CPU time.
- Gaming the Scheduler: Processes may attempt to trick the scheduler to gain more resources.
- Changing Behavior Over Time: A program's behavior may evolve, affecting its scheduling needs.
Summary of MLFQ
- MLFQ does not require prior knowledge; it determines priority by observing execution behavior.
- Its overall performance is close to that of SJF/STCF.
- It is well-optimized for short, interactive tasks.
- It remains fair to long-running tasks.
Chapter 9: Proportional Share
Objective: To ensure that each process receives a certain percentage of CPU time.
Lottery Scheduling
Each process holds a number of tickets, and the system randomly selects one ticket from all available tickets; the process that owns the selected ticket gets to execute.
According to the law of large numbers, as execution time increases, the percentage of execution time allocated to each process will eventually converge to the proportion of tickets it holds relative to the total number of tickets.
Basic Concepts
- Currency: Each user can define their own ticket unit and allocate tickets to their subprocesses based on an exchange rate.
- Transfer: A process can temporarily transfer its tickets to another process, effectively relinquishing its execution rights.
- Inflation: In an environment where processes trust each other, a process can inflate its ticket count to gain more CPU time without notifying other processes.
Implementation
A random number generator is used to select the winning ticket, along with a data structure (such as a list) that records all processes in the system and the total number of tickets.
Assume we use a list to track processes. There are three processes: A, B, and C. Before making a scheduling decision, a random number (the winning ticket) is selected from the total number of tickets, say 400. Suppose the number 300 is chosen. Then, we traverse the linked list, using a simple counter to help identify the winner.
We traverse the process list from the beginning, adding the value of each ticket to the counter until the counter exceeds the winning number. At that point, the current list element corresponds to the winning process. For example, if the winning ticket is 300, we first add A's tickets: the counter increases to 100. Since 100 < 300, we continue. Then, the counter increases to 150 (B's tickets), still less than 300, so we continue. Finally, when the counter increases to 400 (greater than 300), we stop, and the current pointer indicates that C is the winner.

- Advantages: Lightweight, requiring almost no state recording; fast execution.
- Disadvantages: Cannot guarantee correct proportional allocation when job runtimes are very short.
Stride Scheduling
Eliminates randomness by replacing it with a fixed stride, resulting in a deterministic and fair allocation algorithm.
Steps
- For example, if tickets for
A, B, Care100, 50, 250, respectively, set their strides as the inverse of their tickets (a simple approach is to divide a large number by each ticket). If this large number is10000, then the strides forA, B, Care100, 200, 40. - Initialize the total strides for
A, B, Cto 0. - Select the process with the smallest total stride and add its stride value to it.
- Repeat step 3.
The final scheduling result is shown in the figure below:
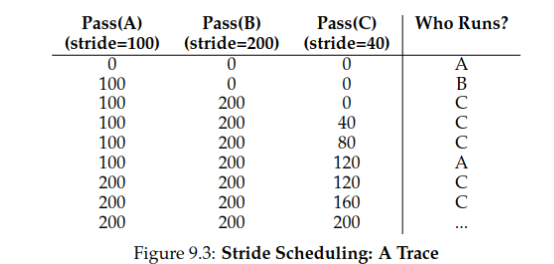
- Advantage: The percentage of execution time for each process exactly matches the proportion of its tickets (rather than gradually converging to this value).
- Disadvantage: Inconvenient for adding new processes.
Linux CFS (Optional Topic)
- For each process, balance efficiency and fairness by adjusting
sched_latencyandmin_granularity(consider the drawbacks of too small or too large time slices inRound-Robin). - Adjust the weight of a process using the
niceshell command. Specifically, the time slice for each process can be calculated using the following formula:
Refer to the following definition for specific weight constants:
// the map between nice param to weight
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
- Track the current runtime of a program using
vruntime(which may not be real time but can be understood as the stride mentioned above). Select the process with the smallestvruntimefor the next run. Specifically, for everyruntimeamount of time executed, updatevruntimeusing the following formula:
Here, the value of weight_0 can be found in the code above and is 1024.
- Use a red-black tree for process management. Specifically, this data structure ensures that the time complexity for process insertion, query (finding the process with the smallest
vruntime), modification, and deletion is uniformlyO(log n), as opposed toO(n)with a regular list. - For processes performing I/O operations or sleeping, the system sets their
vruntimeto the minimumvruntimeamong all other processes.
Summary
In this chapter, we learned about:
- Two methods of proportional scheduling: lottery scheduling and stride scheduling.
- Linux CFS: dynamic time slices, weights, red-black trees, and I/O handling.